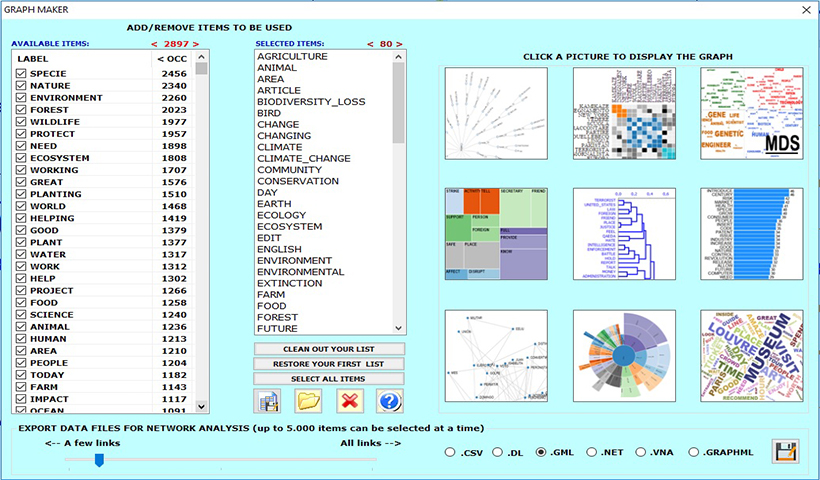
T-LAB offers one of the most complete, easy-to-use, flexible and transparent software environments for content analysis and text mining.
What?

T-LAB software is an all-in-one set of linguistic, statistical and graphical tools designed to allow you to enjoy text analysis.
Many types of texts can be analysed: speech transcripts, newspaper articles, responses to open-ended questions, Twitter messages, transcripts of interviews and focus groups, legislative texts, patents, company documents, books, etc.
More than ten different formats - either documents or tabular data - are supported: .txt, .doc, .docx, .pdf, .rtf, .html, .xls, .xlsx, .csv, .mdb, .accdb, .sav, .json, .xml.
Texts in all languages can be analysed, including those using ideograms. The whole corpus and its subsets can be analysed by using easily customizable key-term lists.
Click here to find out what T-LAB does and what T-LAB enables you to do.
Who?
T-LAB is used in more than forty countries, and highly valued both by researchers in leading universities, and professional analysts across many fields.
They include sociologists, marketing consultants, psychologists, political scientists, economists, linguists, philosophers, public administration managers, anthropologists, historians, psychiatrists etc.
Find out more about our customers and related bibliography
Why?
T-LAB uses a kind of text-driven automatic approach which allows meaningful patterns of words and themes to emerge.
T-LAB’s architecture actually encourages you to be intrigued by the circular transformations in your data and to explore them fully.
All processes are transparent and can be easily customized.
Various analysis methods can be applied.
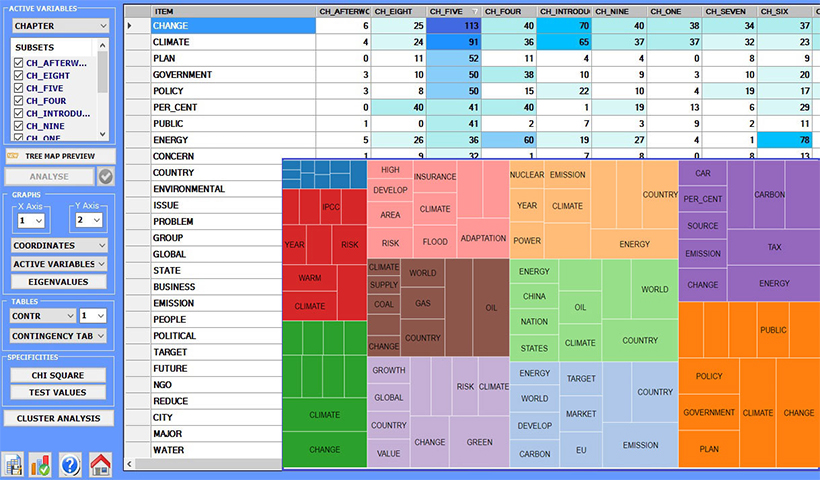
Tables and charts are interactive and can be exported in various formats.
The user's interface, the contextual help and the manual are in four languages: English, French, Spanish, Italian.
How?
Once the text is processed T-LAB knows each word, each sentence and each document through and through.
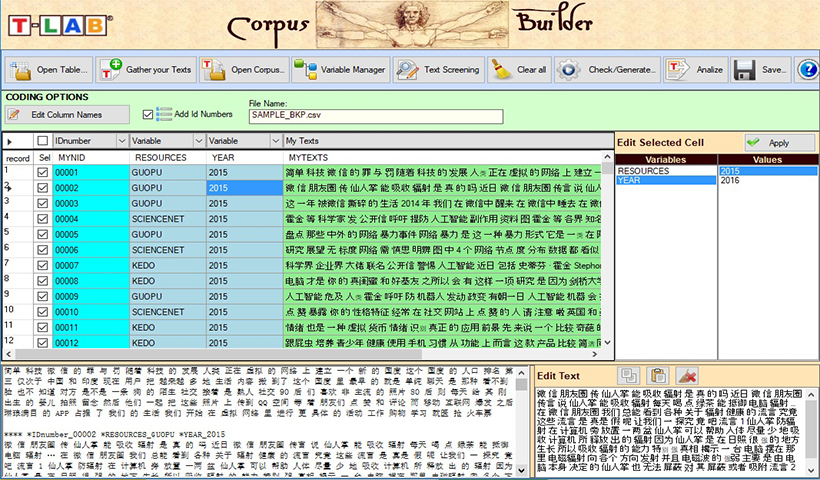
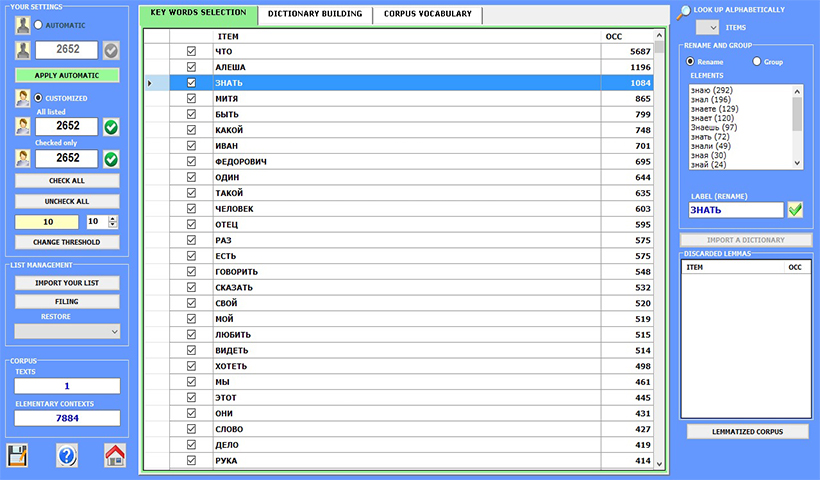
The pre-processing steps include: text segmentation, automatic lemmatisation or stemming, multi-word and stop-word detection, key-term selection.
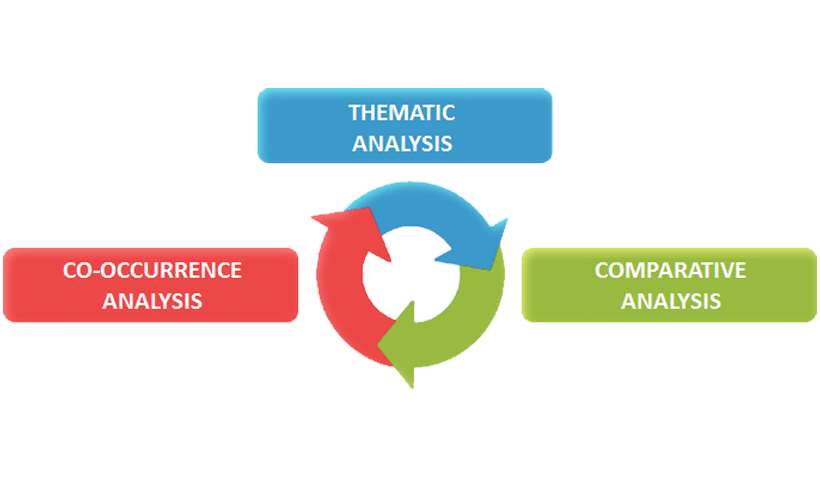
Subsequently, three sub-menus allow easy browsing between several analysis tools.
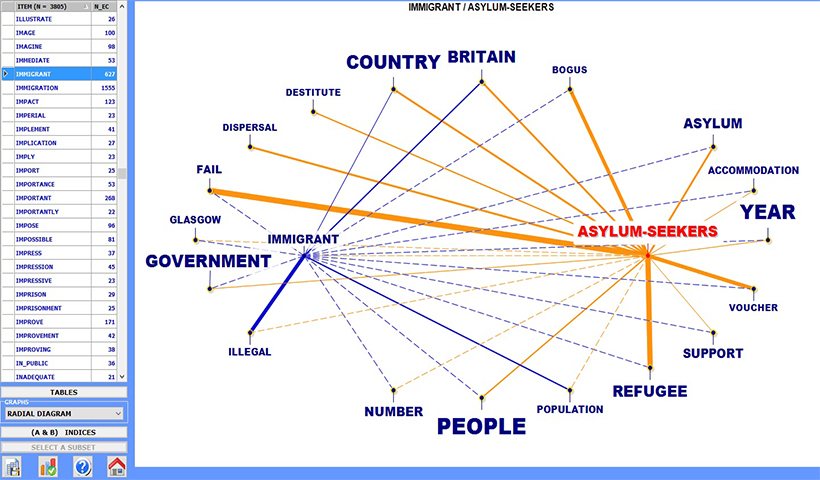
The co-occurrence analysis tools allow measuring, exploring and mapping of various types of relationships between key-terms either in pairs or in groups, either within the entire corpus or within its subsets (i.e. newspaper articles from specific time periods, interviews with people belonging to the same demographic category, etc.).
The thematic analysis tools deal mostly with finding patterns of key-words within context units. Actually the way T-LAB allows us to manage thematic analysis is unique. In fact all analysis units (i.e. words, text segments and documents) can be grouped either by a bottom-up or a top-down approach.
The comparative analysis tools enable us to analyse and map similarities and differences between corpus subsets, each of which has a specific lexical profile resulting from the key-terms which occur in it. Both similarities and differences can be explored either between pairs or within groups.
Click here to see a descriptive example.
T-LAB is available for Windows platforms (Windows 7,8,10,11).
The user's interface, the contextual help and the manual are in four languages: English, French, Italian, Spanish.
MAC users interested in using T-LAB must have Microsoft Windows active on their computer.
The table below summarizes the main characteristics of T-LAB.
Text in all languages, including those using ideograms
(i.e. files in UTF-8 format).
The maximum size of a corpus is 90 MB, equal to about 55,000 pages in text format.
Document formats which can be processed: .txt, .doc, .docx, .pdf, .rtf, .html, .xls, .xlsx, .csv, .mdb, .accdb, .sav, .json, .xml (N.B. The image-only PDF files must processed using OCR software first)
Languages for which LEMMATIZATION is supported :
Catalan, Croatian, English, French, German, Italian, Latin, Polish, Portuguese, Romanian, Russian, Serbian, Slovak, Spanish, Swedish, Ukrainian
Languages for which STEMMING is supported:
Arabic, Bengali, Bulgarian, Czech, Danish, Dutch, Finnish, Greek, Hindi, Hungarian, Indonesian, Marathi, Norwegian, Persian, Turkish
During the importation phase, T-LAB performs a corpus segmentation for the co-occurrences computation. According to the user's choices, the text segments (i.e. elementary contexts) can be of four types: 1) Sentences; 2) Chunks; 3) Paragraphs; 4) Short texts (e.g. Tweets)
Texts and documents may be analyzed and compared through the use of variables defined by the user. Currently, the number of available categorical variables is fixed at 50, each allowing subdivision of the corpus into as many as 150 subsets which can be compared.