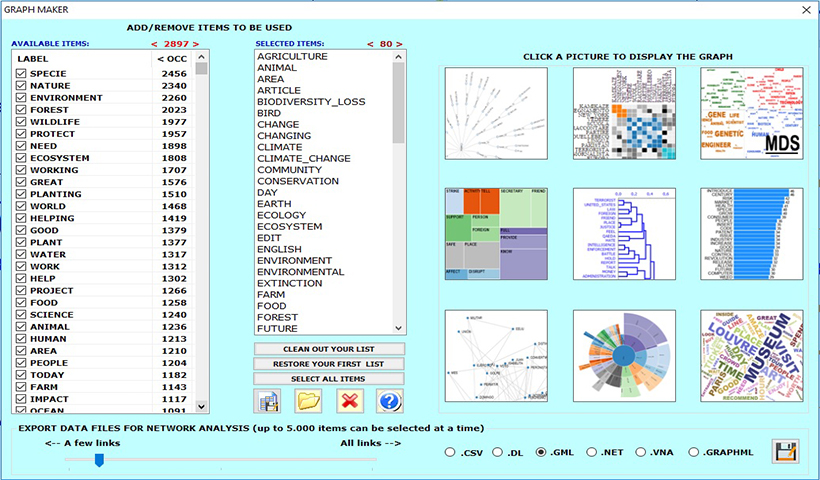
T-LAB ofrece un ambiente software para el análisis del contenido y para la minería de textos entre los más completos, flexibles, transparentes y fáciles de usar del mercado.
¿Qué?

El software T-LAB se compone de un conjunto de herramientas lingüísticas, estadísticas y gráficas diseñadas para que el análisis de los textos sea una experiencia agradable e interesante.
Los textos a analizar pueden ser de varios tipos: artículos de periódicos, transcripciones de entrevistas y discursos, respuestas a preguntas abiertas, mensajes Twitter, documentos empresariales, textos legislativos, libros, etc.
Los formatos de documentos y tablas admitidos en la fase de importación son: .txt, .doc, .docx, .pdf, .rtf, .html, .xls, .xlsx, .csv, .mdb, .accdb, .sav, .json, .xml.
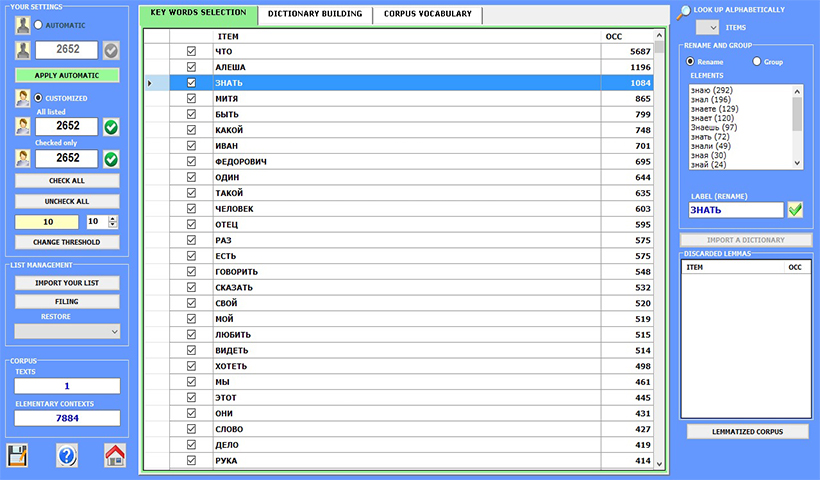
Es posible analizar textos escritos en todos los idiomas, incluidos aquellos basados en ideogramas.Todo el corpus y sus subconjuntos se pueden analizar utilizando listas de palabras clave fácilmente personalizables.
Haga clic aquí para descubrir qué hace T-LAB y qué T-LAB permite hacer.
¿Quien?
Actualmente T-LAB viene utilizado en más de cuarenta países del mundo. Además, es muy valorado tanto por la comunidad académica como por numerosos profesionistas que operan en sectores diferentes.
Los usuarios son sociólogos, psicólogos, antropólogos, asesores de marketing, politólogos, economistas, dirigentes de administraciones públicas, lingüistas, historiadores, psiquiatras, filósofos etc.
Haga clic aquí para consultar la lista de los usuarios y la bibliografía.
¿Por qué?
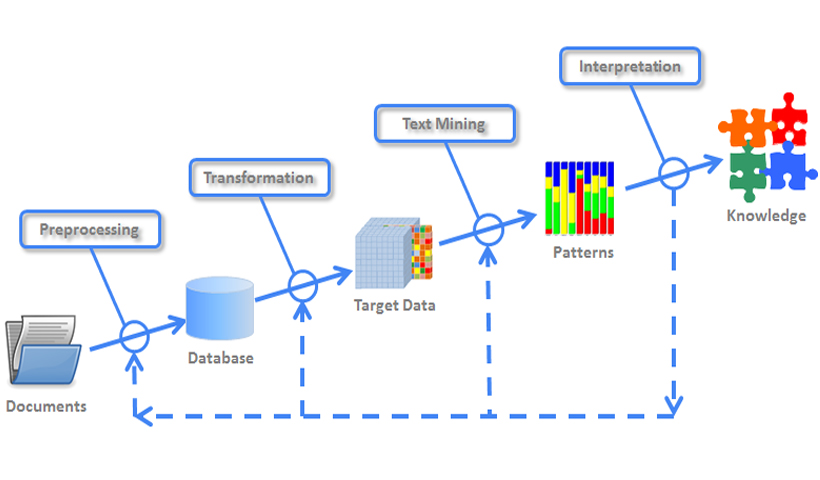
T-LAB utiliza análisis automáticos que permiten extraer patrones basados en palabras y temas significativos.
La arquitectura de T-LAB estimula la curiosidad del investigador, le intriga gracias a las transformaciones circulares de los datos y le ayuda a construir sus interpretaciones.
Todos los procesos son transparentes y pueden ser personalizados.
La gama de herramientas para los análisis es amplia y flexible.
Tablas y gráficos son interactivos y además pueden ser exportados en diferentes formatos.
La interfaz del usuario, la ayuda contextual y el Manual del Usuario están en cuatro idiomas: Español, Francés, Inglés, Italiano.
¿Cómo?
Al terminar el procesamiento del texto, T-LAB dispondrá de un archivo en el que aparecerán informaciones detalladas sobre las palabras, frases y documentos recogidos en el texto mismo.
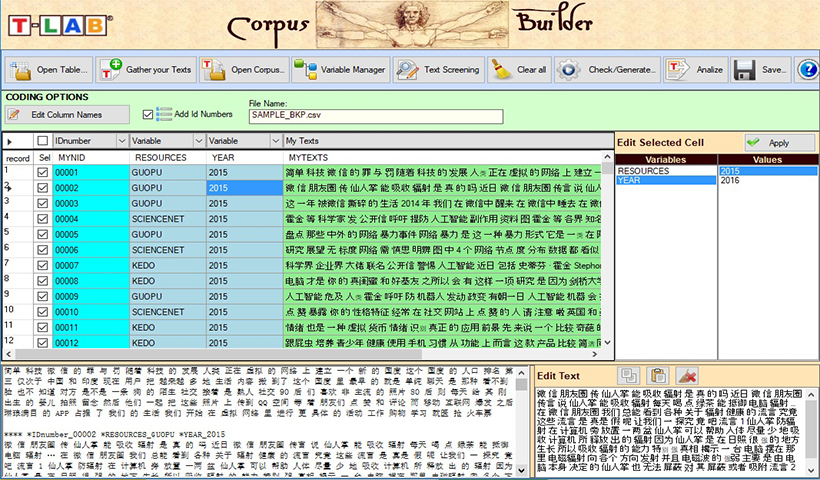
Durante el proceso de importación, T-LAB realiza los tratamientos siguientes: normalización del corpus, detección de multi-palabras y palabras vacías, segmentación en contextos elementales, lematización automática o stemming, selección de palabras clave.
Sucesivamente, es posible utilizar tres herramientas que permiten implementar varios tipos de exploración y de análisis.
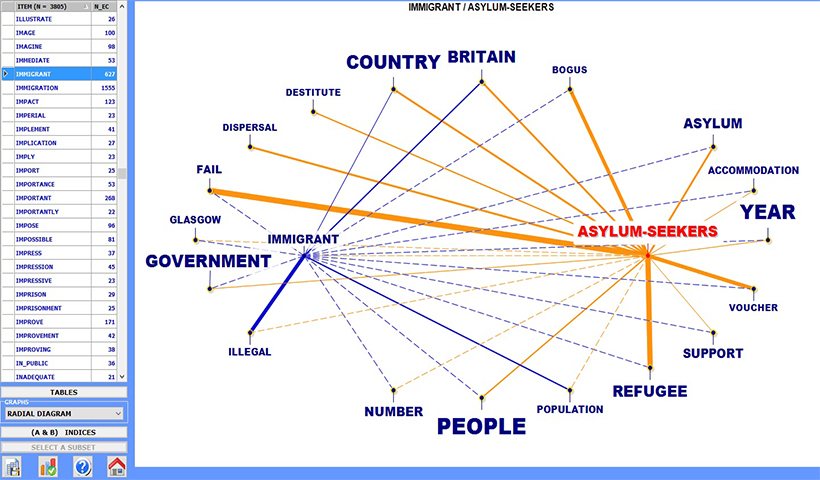
Las herramientas para el análisis de las co-ocurrencias permiten explorar, medir y mapear diferentes tipos de relación entre palabras clave. Todo ello, tanto considerando parejas como grupos de palabras, que pueden proceder del corpus en su conjunto de subapartados del mismo (ejemplo: artículos de un mismo periódico, entrevistas con personas de la misma categoría demográfica etc.).
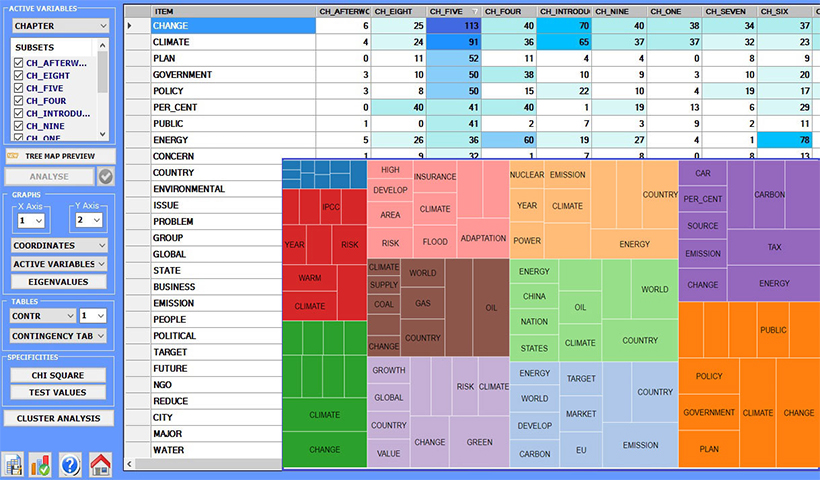
Las herramientas para los análisis temáticos están principalmente orientadas a la búsqueda de patrones de palabras clave dentro de las unidades de contexto. En efecto, la forma con la que T-LAB permite gestionar el análisis temático es bastante sofisticado, ya que todas las unidades de análisis (es decir, palabras, segmentos de texto y documentos) pueden ser clusterizadas tanto mediante un procedimiento "bottom-up" como "top-down".
Las herramientas de análisis comparativo permiten analizar y mapear las diferencias y las similitudes entre los distintos subapartados del corpus. Cada uno de ellos se caracteriza por un perfil lexical, generado a partir de las palabras clave en ello contenidas (ocurrencias). Tanto las diferencias como las similitudes pueden ser exploradas comparando entre sí los subapartados. Dicha comparación puede surgir tanto entre subapartados individuales como entre grupos de subapartados.
Haga clic aquí para ver un ejemplo descriptivo.
T-LAB ha sido ideado para ambientes Windows (7, 8, 10, 11).
La interfaz del usuario, la ayuda contextual y el Manual del Usuario están en cuatro idiomas: Español, Francés, Inglés, Italiano.
Los usuarios de MAC que quieran utilizar T-LAB necesitan activar Microsoft Windows en sus ordenadores.
En la tabla presentada a continuación se incluyen las principales características de T-LAB.
Textos escritos en todos los idiomas, incluidos aquellos que se fundamentan en ideogramas
(archivos en formato UTF-8).
Tamaño máximo de un archivo corpus: 90 MB (casi 55.000 páginas en formato texto).
Formatos de documentos que se pueden procesar: .txt, .doc, .docx, .pdf, .rtf, .html, .xls, .xlsx, .csv, .mdb, .accdb, .sav, .json, .xml (NOTA: Los archivos PDF de sólo imagen deben ser procesados utilizando el software de OCR por adelantado)
Idiomas para los cuales la LEMMATIZACIÓN está disponible:
Alemán, Catalán, Croata, Eslovaco, Español, Francés, Inglés, Italiano, Latín,Polaco, Portugués, Rumano, Ruso, Serbio, Sueco, Ucraniano
Idiomas para los cuales el STEMMING está disponible:
Árabe, Bengalí, Búlgaro, Checo, Danés, Holandés, Finlandés, Griego, Hindi, Húngaro, Indonesio, Marathi, Noruego, Persa, Turco
Durante la fase de importación, T-LAB realiza una segmentación de corpus para el cálculo de co-ocurrencias. De acuerdo con las elecciones del usuario, los segmentos de texto (es decir, contextos elementales) pueden ser de cuatro tipos: 1) Frases ; 2) Segmentos; 3) Párrafos; 4) Textos Breves (por ejemplo, Tweets)
Textos y documentos pueden ser analizados y comparados por medio del empleo de variables categóricas definidas por el usuario. El número de variables disponibles está fijado en 50; cada una permite una subdivisión del corpus de hasta 150 partes comparables entre ellas.