|
www.tlab.it
Mots Associés et Cartes
Conceptuelles
 N.B.: Les images de cette section font référence à une
version précédente de T-LAB. En
T-LAB 10, l'aspect est
légèrement différent. En outre: a) quand la 'sélection automatique
des mots-clés' est sélectionnée, dans la carte MDS des différentes couleurs sont utilisées pour
indiquer différents clusters d'éléments; b) la technique de
visualisation appelée t-SNE (t-Distributed Stochastic Neighbor
Embedding) a été ajoutée; c) un nouveau bouton (Graph Maker) qui permet à l'utilisateur de créer
plusieurs graphiques dynamiques en format HTML est disponible; d)
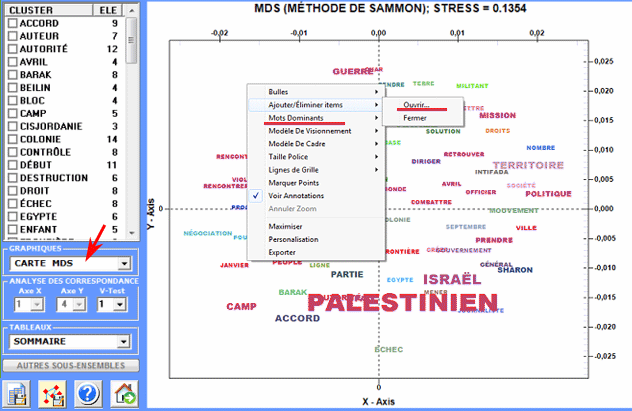
le bouton droit sur les graphiques ou
sur les tableaux avec les mots-clés rend disponible certaines
options additionnelles; e) une galerie d'images à accès rapide qui
fonctionne comme un menu supplémentaire permet de basculer entre
les différentes sorties en un seul clic. N.B.: Les images de cette section font référence à une
version précédente de T-LAB. En
T-LAB 10, l'aspect est
légèrement différent. En outre: a) quand la 'sélection automatique
des mots-clés' est sélectionnée, dans la carte MDS des différentes couleurs sont utilisées pour
indiquer différents clusters d'éléments; b) la technique de
visualisation appelée t-SNE (t-Distributed Stochastic Neighbor
Embedding) a été ajoutée; c) un nouveau bouton (Graph Maker) qui permet à l'utilisateur de créer
plusieurs graphiques dynamiques en format HTML est disponible; d)
le bouton droit sur les graphiques ou
sur les tableaux avec les mots-clés rend disponible certaines
options additionnelles; e) une galerie d'images à accès rapide qui
fonctionne comme un menu supplémentaire permet de basculer entre
les différentes sorties en un seul clic.
Certaines de ces nouvelles fonctionnalités sont mises en évidence
dans l'image ci-dessous.
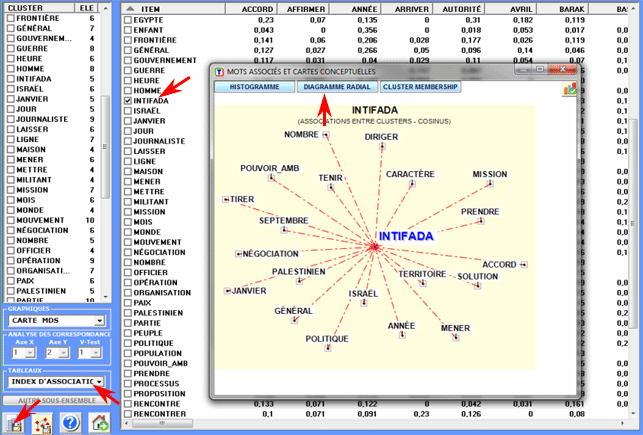
Cet outil T-LAB nous permet d'analyser deux types de
relations concernant les co-occurrences
des mots:
A - entre les mots-clés(lemmes ou catégories) sélectionnés, si
leur quantité n'excède pas 500 éléments (minimum
10);
B - entre (et à l'intérieur de) clusters (c.-à-d. noyaux
thématiques), si la quantité des mots-clés sélectionnés excède 100
éléments (maximum 3.000).
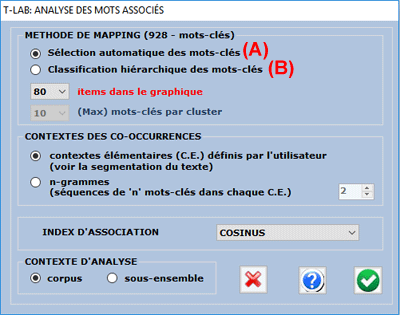
L'utilisateur peut choisir l'index d'association à employer et, seulement pour
l'option B, aussi bien la quantité maximum de clusters à obtenir
(de 50 a 100) que la quantité maximum de mots-clés par
cluster.
Le processus de calcul inclut les
étapes suivantes:
1-
construction d'une matrice des cooccurrences (mot x mot);
2- calcul des index d'association sélectionnés (Cosinus, Dice,
Jaccard, Equivalence, Inclusion, Information Mutuelle);
3-
classification hiérarchique;
4- construction d'une deuxième matrice des cooccurrences (cluster x
cluster);
5- représentation de graphique par multidimensional scaling et
analyse de correspondances.
N.B:
- dans le cas (A) (voir ci-dessus), l'utilisateur peut revoir et
personnaliser la sélection des mots-clés (voir l'image suivante)
et T-LAB n'effectue pas les passages 3 et 4;
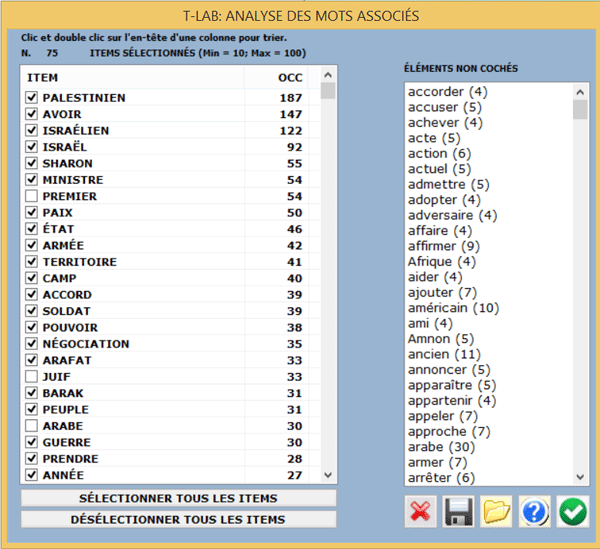
- la qualité des résultats dépend d'une bon choix des mots clés;
- puisque les lexies (multi-words) non classifiées par T-LAB sont
des cas spécifiques de cooccurrence et l'option "B" les traite
comme des petits faisceaux (ex. "Twin" + "Towers"), il est
recommandé de résoudre ces cas pendant la phase de prétraitement. Dans tous les cas,
sans répéter l'importation de corpus, il est possible de faire des
changements au moyen de l'outil Personnalisation du Dictionnaire (par exemple en
assignant l'étiquette "Twin_Towers" aux deux items différents
"Twin" + "Towers");
- tous les tableaux de données peuvent être vérifiés en cliquant
sur les boutons appropriés (voir ci-dessous).
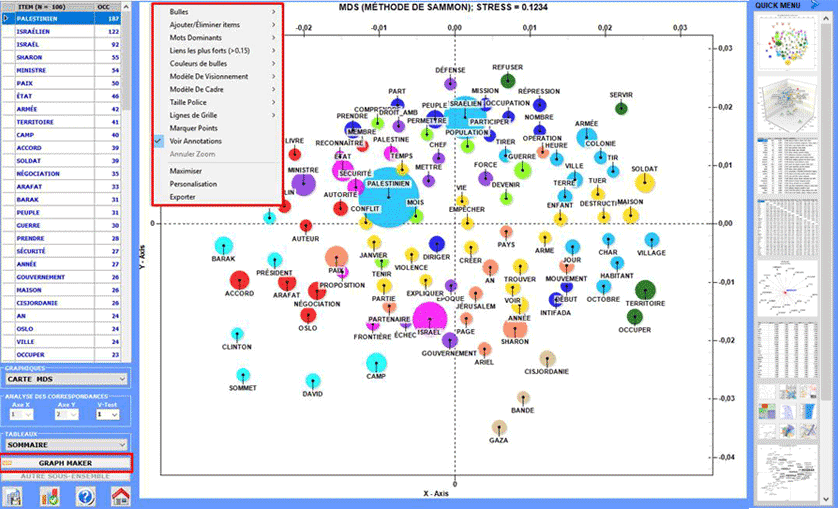
Après l'analyse automatique, l'utilisateur peut
visualiser quatre types de diagrammes et - en employant le bouton
droit de la souris - ouvrir une fenêtre de dialogue qui permet
plusieurs personnalisations.
1 - Carte MDS
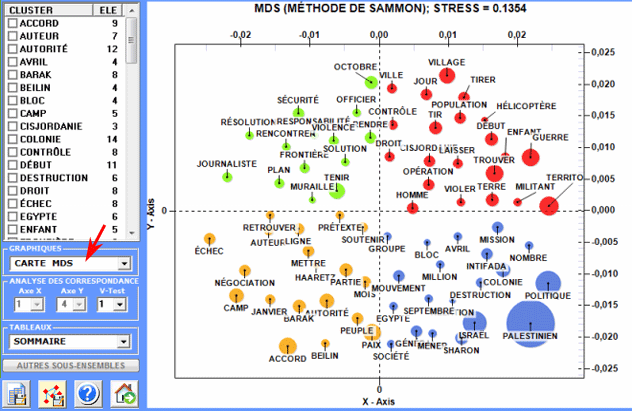
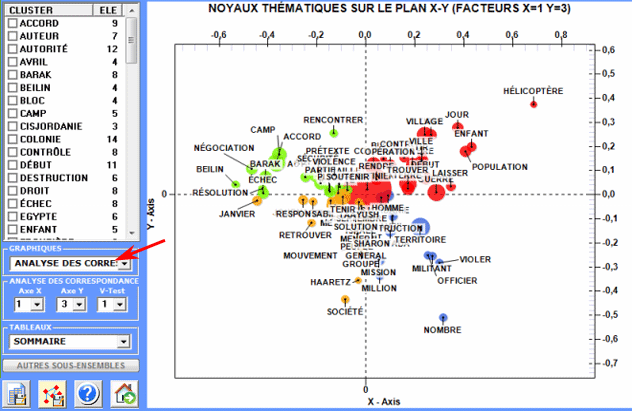
2 - Analyse Factorielle des Correspondances
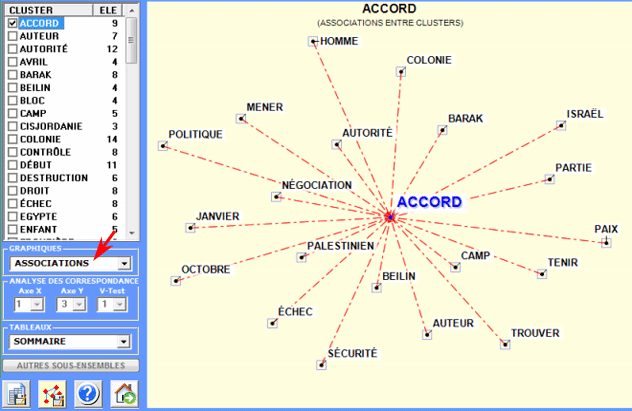
3 - Diagramme des Associations
4 - Carte avec les mesures de Centralité et
Densité (seulement après une cluster analysis)
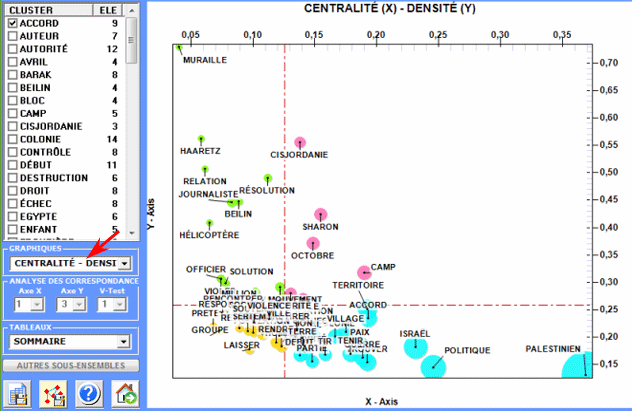
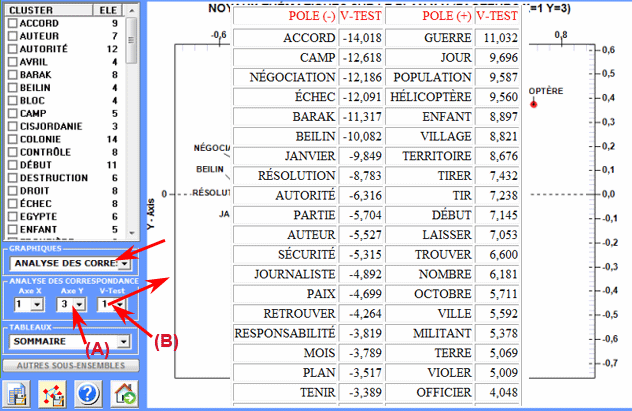
En particulier, les résultats obtenus par
l'Analyse des Correspondances peuvent
être représentés en utilisant les coordonnées des dix premiers axes
(voir "A" ci-dessous). Puisque T-LAB nous permet de vérifier les Valeurs Test de chaque facteur (voir "B"
ci-dessous), ce genre de output peut être employé pour une
interprétation attentive des rapports entre les clusters et/ou
entre les mots-clés.
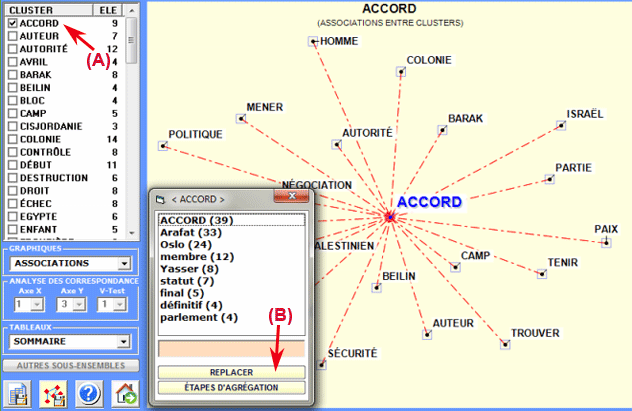
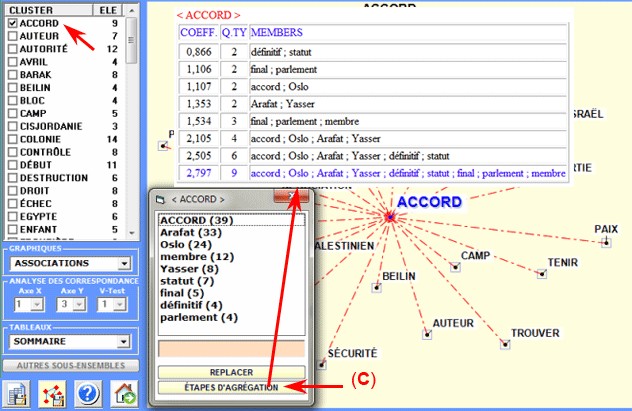
Les diagrammes peuvent être explorés et
personnalisés de manières suivantes:
|
ACTION
|
RÉSULTAT
|
|
clic sur un item du tableau
ou sur un point du graphique
|
diagramme des associations
|
|
double clic sur une étiquette de la colonne
"CLUSTER" (voir "A" ci-dessous )
|
liste avec les éléments du cluster
|
|
clic sur le bouton "Replacer" (voir "B"
ci-dessous)
|
nouvelle étiquette assignée au cluster
|
|
clic sur le bouton "étapes d'agrégation" (voir
"C" ci-dessous)
|
étapes d'agrégation dans le cluster
|
|
bouton droit de la souris
|
personnalisations des graphiques
|
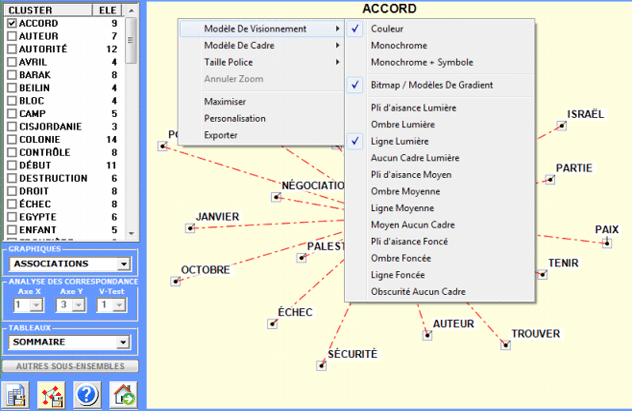
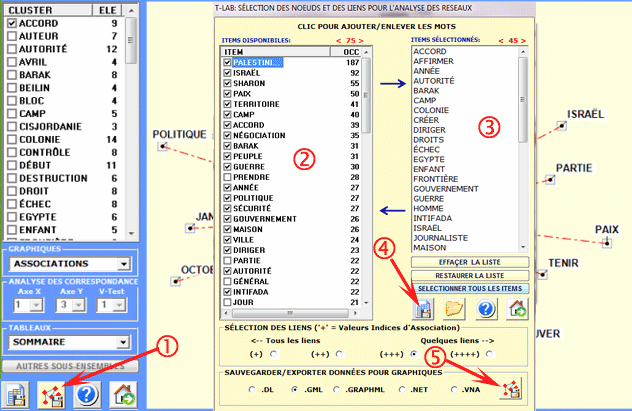
Une autre fenêtre T-LAB (voir image suivante, étape 1) permet de
créer des fichiers graphiques qui peuvent être édités avec un
logiciel pour l'analyse des reseaux
tel que Gephi, Pajek, Ucinet, yEd et d'autres. Dans ce cas, les
options disponibles sont les suivantes: sélectionner les items
(c'est-à-dire les "nœuds") à insérer dans les graphiques (voir
ci-dessous, étapes 2 et 3), exporter la matrice correspondante de
proximité (voir ci-dessous, étape 4), sélectionner les liens en
base à leurs index d'association et exporter le type de fichier
choisi (voir ci- dessous, étape 5).
N.B.: En T-LAB 10 la
fenêtre suivante a été remplacée par l’outil Graph Maker.
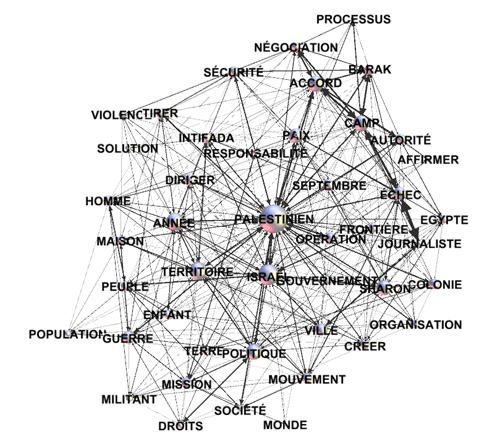
Par exemple, un fichier .gml exporté par
T-LAB peut permettre de réaliser un graphique
comme le suivant.
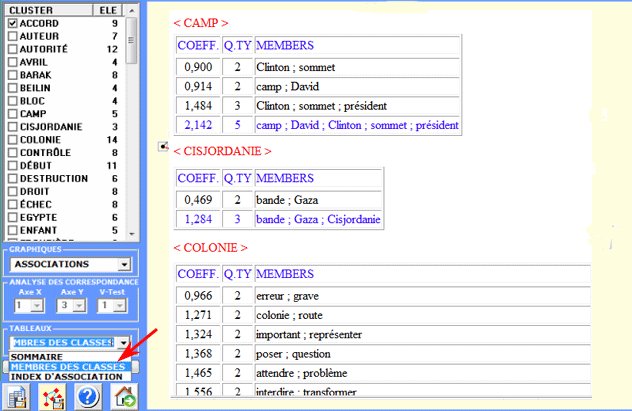
Les tableaux exportables avec cet instrument
T-LAB sont de trois types:
1 - le tableau "Membres des classes" (voir
ci-dessous) concerne l'agrégation hiérarchique des mots dans chaque
cluster;
2 - le tableau "Sommaire" (voir
ci-dessous) inclut les mesures suivantes:
- ECQ = quantité de contextes élémentaires dans
lesquels deux mots (ou plus) de chaque cluster sont
co-occurrentes;
- Centrality = moyenne des index d'association concernant les
rapports entre clusters;
- Density = moyenne des index d'association des mots dans chaque
cluster.
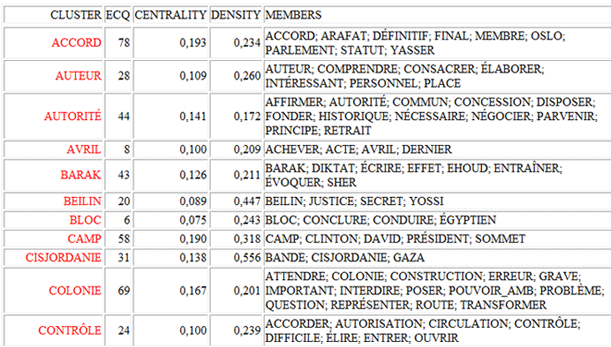
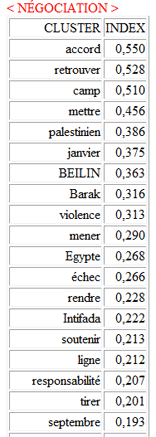
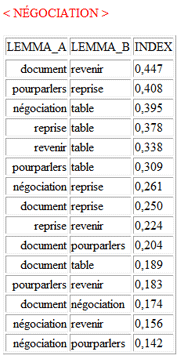
3 - le tableau "Index d'Association"
(voir ci-dessous) inclut des mesures de similitude concernant les
rapports entre (between) et dans (within) les clusters.
|
Between
|
Within
|
|
|
N.B.:
- Quand la
cluster analysis n'a pas été réalisée, le tableau "Membres des
classes" n'est pas disponible, le tableau "Sommaire" est simplifié
et le tableau "Index d'Association" concerne seulement les
co-occurrences des mots;
- Lorsqu'on quitte cette analyse, le dictionnaire des noyaux
thématiques (c.-à-d. la liste des étiquettes assignées à chaque
faisceau de mots) peut être exporté et, après une attentive
révision, peut être importé en utilisant l'outil Personnalisation du Dictionnaire. De cette façon
l'utilisateur pourra réaliser quelques analyses du deuxième ordre
(c.-à-d. analyses qui concernent "thèmes" ou
"concepts").
|


