|
www.tlab.it
Indici di
associazione
In T-LAB gli
indici di associazione (o di similarità) sono utilizzati per
analizzare le co-occorrenze delle
unità lessicali (LU, lexical units)
all'interno dei contesti elementari (EC,
elementary contexts), cioè dati binari del tipo
presenza/assenza.
Ad esempio, dati due LU e dieci EC, possiamo costruire il
seguente esempio:
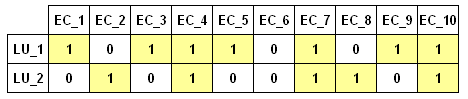
Gli stessi dati possono essere rappresentati nel
modo seguente:
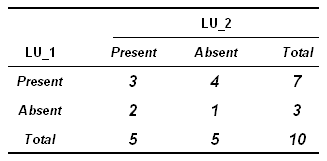
Generalizzando e utilizzando le lettere
dell'alfabeto:
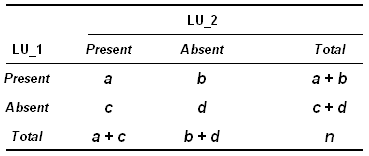
Le formule corrispondenti ai sei indici di
associazione usati da T-LAB
sono le seguenti:
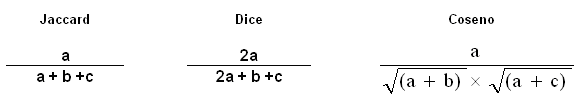
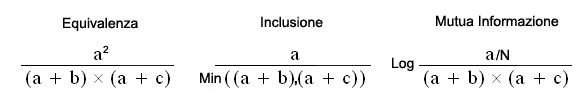
Ipotizzando di aver ottenuto indici di associazione
delle relazioni tra dieci LU, possiamo costruire una tabella come
la seguente:
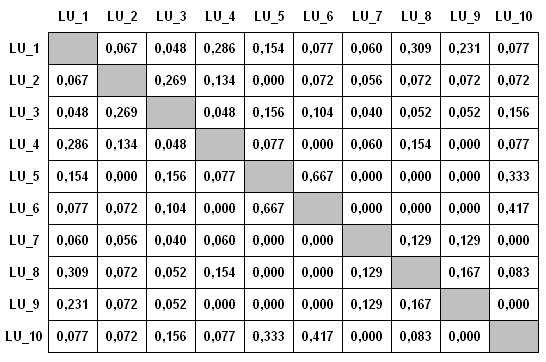
Di fatto, T-LAB
costruisce ed analizza tabelle analoghe di dimensioni N x N (dove N
può corrispondere a varie centinaia di colonne), sia mediante
Multidimensional Scaling che mediante
Cluster Analysis.
Tabelle simili sono anche utilizzate per
calcolare indici di similarità del secondo
ordine tra coppie di parole chiave (vedi lo strumento
Associazioni di Parole).
|


