|
www.tlab.it
Classificazione basata su
Dizionari
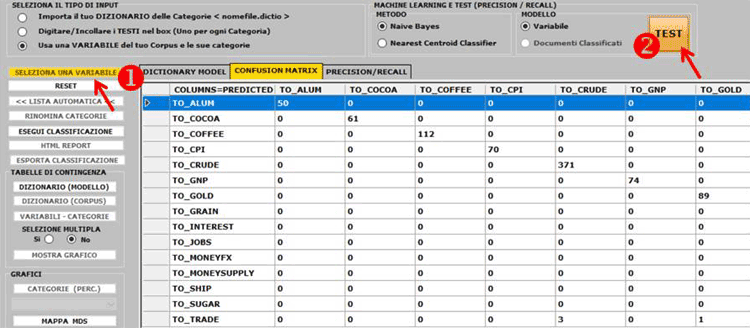
 N.B.: Le immagini di questa sezione fanno riferimento a una
versione precedente di T-LAB.
In T-LAB 10 l'aspetto è
leggermente diverso. In particolare, a partire dalla versione 2021,
una nuova funzionalità consente di testare facilmente qualsiasi
modello su dati etichettati (es. dati che includono temi ottenuti
da una precedente analisi qualitativa) e ottenere output come
matrici di confusione e metriche di precision / recall (vedi
immagine seguente).
N.B.: Le immagini di questa sezione fanno riferimento a una
versione precedente di T-LAB.
In T-LAB 10 l'aspetto è
leggermente diverso. In particolare, a partire dalla versione 2021,
una nuova funzionalità consente di testare facilmente qualsiasi
modello su dati etichettati (es. dati che includono temi ottenuti
da una precedente analisi qualitativa) e ottenere output come
matrici di confusione e metriche di precision / recall (vedi
immagine seguente).
Questo strumento T-LAB permette di eseguire una classificazione automatica delle unità lessicali (cioè parole e lemmi, incluse
multiwords) o delle unità di contesto
(cioè frasi, paragrafi o documenti brevi) presenti in un corpus
applicando un insieme di categorie pre-definite o scelte
dall'utilizzatore.
A seconda del tipo di categorie usate, le quali possono
essere contenute in un dizionario opportunamente importato o
generate da T-LAB, tale
classificazione può essere considerata un tipo di analisi del contenuto o un tipo di sentiment analysis.
Poiché il processo di analisi consente di creare nuove
variabili e altri dizionari che possono essere esportati e
importati in ulteriori progetti di analisi, tale strumento può
essere usato anche per esplorare lo stesso corpus da prospettive
diverse così come per analizzare due o più insiemi di testi
applicando gli stessi modelli.
Tra i possibili usi di
questo strumento, segnaliamo i seguenti:
- Codifica automatica di risposte a domande aperte;
- Analisi top-down dei discorsi politici;
- Sentiment Analysis di commenti concernenti specifici
prodotti;
- Verifica del processo psicoterapeutico;
- Validazione di metodi per l'analisi qualitativa.
Di seguito viene fornita una breve descrizione delle
quattro fasi principali del processo di analisi, che - tuttavia -
sono da considerarsi indipendenti l'una dall'altra. Infatti, il
ricercatore può utilizzare questo strumento anche solo per
personalizzare i suoi dizionari o per esplorare il suo set di
dati.
A) - FASE DI PRE-PROCESSING
I punti di partenza e i corrispondenti tipi di input della fase di pre-processing possono
essere tre:
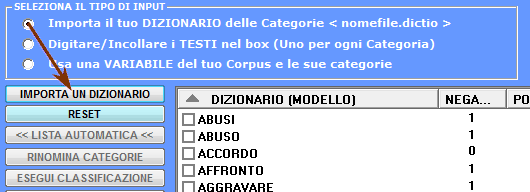
1 - un dizionario delle
categorie nel formato appropriato è già disponibile (vedere le
relative informazioni nella sezione 'E' di questo documento). In
questo caso basta cliccare l'opzione 'Importa un Dizionario' (vedi
sotto);
2 - un dizionario delle categorie deve essere ricavato da
esempi di testo o da liste di parole fornite dall'utilizzatore. In
questo caso, è sufficiente digitare o copiare / incollare i testi
nella casella appropriata (un esempio per ogni categoria, uno dopo
l'altro, max 100.000 caratteri ciascuno);

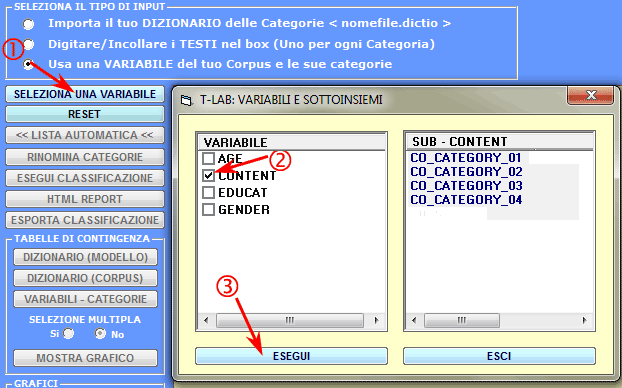
3 - un dizionario delle categorie deve essere ricavato da
una variabile derivante da una
precedente analisi di contenuto. In questo caso, basta cliccare
l'opzione 'Seleziona una Variabile' ed effettuare le scelte
appropriate (vedi sotto).
A seconda dei tre casi sopra elencati, prima di abilitare l'opzione
'Esegui Classificazione', T-LAB
funziona nel modo seguente:
1 - il dizionario importato viene trasformato in una
tabella di contingenza che l'utilizzatore può esplorare in vari
modi (vedere la sezione 'C' del presente documento); inoltre,
selezionando ogni categoria, uno o più degli elementi
corrispondenti possono essere eliminati (vedi immagine
seguente).
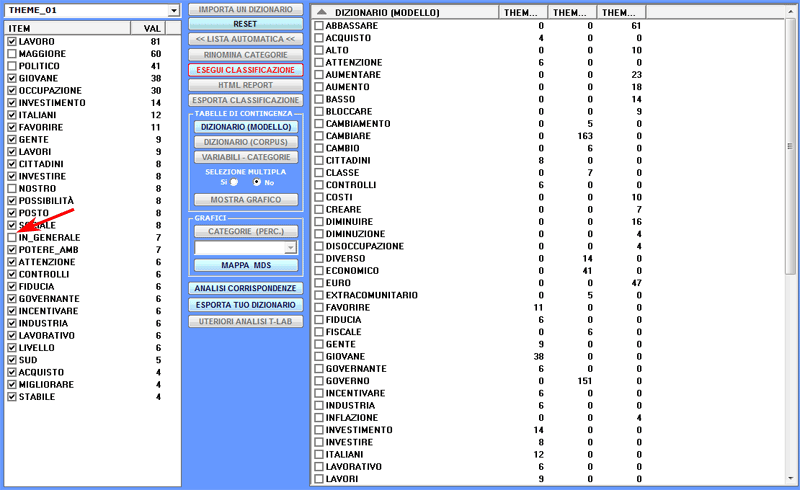
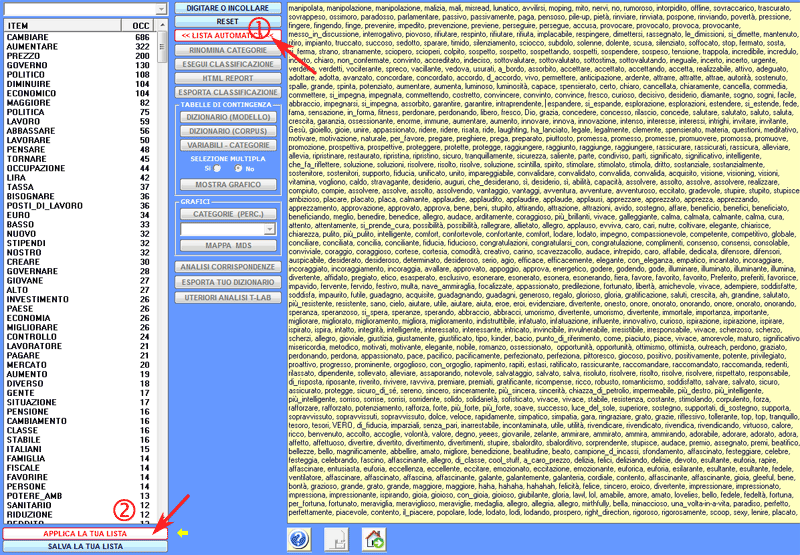
2 - quando i testi di esempio sono inseriti nella casella
corrispondente, dopo aver cliccato il pulsante 'Lista Automatica'
(vedi sotto), T-LAB esegue uno
specifico tipo di lemmatizzazione che utilizza solo il vocabolario
del corpus selezionato (vedi la lista di parole nella zona sinistra
dell'immagine seguente), quindi trasforma ogni testo in un elenco i
cui elementi possono essere selezionati e deselezionati.
Successivamente, per convalidare ogni lista di parole (cioè ogni
categoria del dizionario), bisogna cliccare l'opzione 'Applica la
tua lista' (vedi sotto). Tutte le suddette operazioni devono essere
ripetute per ogni categoria del dizionario, dopodiché
l'utilizzatore viene abilitato ad eseguire le operazioni descritte
nella sezione 'C' di questo documento.
3 - quando viene selezionata una variabile risultante da
una precedente analisi del contenuto, T-LAB visualizza la relativa tabella di
contingenza parole per categorie e l'utilizzatore può eseguire
tutte le operazioni di esplorazione dei dati (vedere la sezione 'C'
del presente documento).
B) - PROCESSO DI CLASSIFICAZIONE
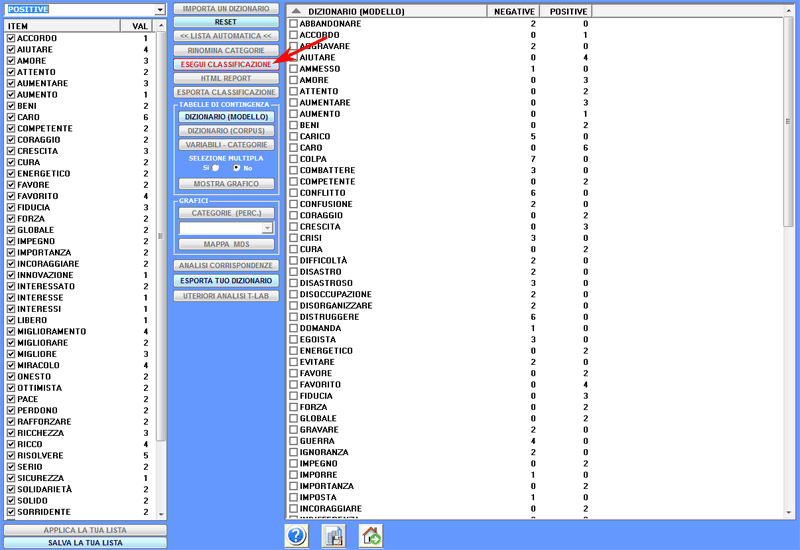
Dopo aver cliccato l'opzione 'Esegui classificazione'
(vedi sopra), a seconda del tipo di corpus in analisi,
l'utilizzatore può effettuare le scelte seguenti:
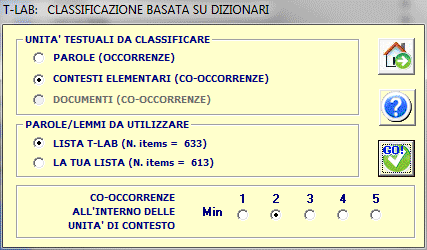
A questo punto, se l'utente decide di classificare le 'parole', non sono disponibili
altre scelte; infatti, in tal caso, le occorrenze di ogni parola
(cioè i word tokens) sono semplicemente conteggiati come occorrenze
della categoria corrispondente. Per esempio, se una categoria del
nostro dizionario è 'religione' e questa include parole come 'fede'
e 'preghiera', quando si analizza un documento che contiene le due
parole in questione, T-LAB si
limita a raggruppare le loro occorrenze. Ad esempio, 2 occorrenze
di 'fede' e 3 occorrenze di 'preghiera' diventano 5 occorrenze di
'religione'.
Diversamente, se l'utente decide di classificare le unità di contesto (e cioè
'contesti elementari' come frasi e paragrafi o 'documenti'),
T-LAB considera sia le
categorie dizionario che le unità di contesto da classificare come
profili di co-occorrenze (cioè term vectors) e calcola le loro
misure di similarità. A questo scopo, i profili di co-occorrenze
posssono essere filtrati tramite una 'Lista T-LAB' (cioè da una
lista che include tutte parole-chiave con valori di occorrenza
maggiori o uguali alla soglia minima di 4) o tramite una lista
personalizzata (cioè da una lista che include tutte parole-chiave
derivanti da scelte dell'utilizzatore) , le quali liste - tuttavia
-possono a volte risultare uguali. Inoltre in questi casi
T-LAB consente di escludere
dall'analisi unità di contesto che non contengano un numero minimo
di parole chiave al loro interno (vedi sopra il parametro
'co-occorrenze all'interno delle unità di contesto').
Quando, come nel caso appena descritto, gli 'oggetti' da
classificare sono le unità di contesto, T-LAB procede nel modo seguente:
a) normalizza i vettori corrispondenti alle 'k' categorie del
dizionario utilizzato, cioè i relativi profili colonna;
b) normalizza i vettori corrispondenti alle unità di contesto da
analizzare;
c) calcola misure di similarità (coseno) e differenza (distanza
euclidea) tra ogni 'i' vettore corrispondente a una unità di
contesto e ogni 'k' vettore corrispondente a una categoria del
dizionario utilizzato;
d) assegna ogni unità di contesto ('i') alla classe o categoria
('k') con la quale ha la relazione di somiglianza più elevata. (NB:
In tutti i casi, per ogni coppia 'unità di contesto' / 'categoria'
deve esserci una corrispondenza tra il massimo valore del coseno e
il minimo valore della distanza euclidea, altrimenti T-LAB
considera la 'i' unità di contesto come 'non
classificata').
In In altre parole, nel caso appena descritto T-LAB utilizza una sorta di metodo K-means in
cui i 'k' centroidi sono definiti priori ed essi non vengono
aggiornati durante il processo di analisi.
Poiché in questo caso la classificazione è di tipo
top-down, la qualità dei risultati ottenuti dipende essenzialmente
da due fattori:
1 - la 'pertinenza' del dizionario utilizzato (vedi relazione tra
lessico del corpus e dizionario delle categorie);
2 - la capacita 'discriminante' di ciascuna delle categorie (vedi
relazione tra le varie categorie del dizionario).
Infatti, quando tali due fattori sono ottimali, entrambi i
parametri di 'precision' e 'recall' (vedi
http://en.wikipedia.org/wiki/Precision_and_recall) hanno valori
compresi tra 80% e 95%.
Si ricordi che, al momento, T-LAB non tiene conto delle formule di
negazione; di conseguenza, effettuando una sentiment analysis, una
frase come 'Non odiare il tuo nemico' può risultare classificata
come a tonalità 'negativa'. Gli utilizzatori esperti possono
gestire questo problema durante l'importazione corpus (vedi l'uso
di liste per stop-words e multi-words). Ad esempio, l'espressione
'non odiare' può essere trasformata in 'non_odiare' e, se lo si
ritiene opportuno, può essere inclusa nella categoria
'positivo'.
C) - ESPLORAZIONE DEI DATI
Nell'uso di questo strumento qualsiasi attività di
esplorazione fa riferimento a tabelle di
contingenza in cui, a seconda dei casi, possono essere
rappresentati sia i dati in input (ad esempio un dizionario di
categorie) che i dati in output (ad esempio i risultati del
processo di classificazione).
In particolare, per quanto riguarda i risultati
dell'analisi, a seconda delle unità testuali classificate -
rispettivamente (a) 'parole', (b) 'contesti elementari' o (c)
'documenti' - le celle delle tabelle visualizzate contengono i
seguenti valori:
a) totale delle occorrenze di ogni parola che, all'interno del
corpus analizzato o di un suo sottoinsieme, è stata classificata
come appartenente ad una categoria predefinita (ovvero alla 'j'
colonna della rispettiva tabella di contingenza). Si noti che in
questo tipo di classificazione le parole appartenenti
contemporaneamente a due o più categorie hanno gli stessi valori
ripetuti nelle colonne corrispondenti;
b) totale dei contesti elementari assegnati ad una determinata
categoria (vale a dire la 'j' colonna) in cui è presente la parola
nella riga ('i') corrispondente;
c) totale delle occorrenze di ogni parola (vedi righe della
relativa tabella di contingenza) all'interno dei documenti
assegnati a ciascuna categoria (vedi colonne della tabella di
contingenza).
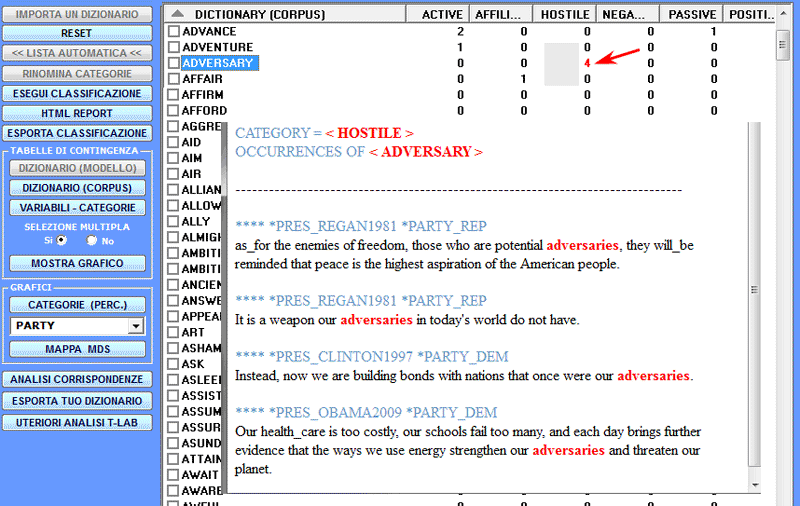
Cliccando i check-box corrispondenti ai vari item in riga
è possibile ottenere grafici che possono essere personalizzati in
vari modi; inoltre, ma solo nel caso della classificazione di tipo
'b' (vedi sopra), cliccando i valori contenuti nelle celle è
possibile visualizzare i contesti di occorrenza di ogni
parola.
Di seguito vengono riportati alcuni output risultanti da
un processo di analisi in cui alcune categorie di un 'classico'
dizionario per l'analisi di contenuto (Harvard IV-4) sono state
applicate ai discorsi inaugurali dei presidenti degli Stati
Uniti.
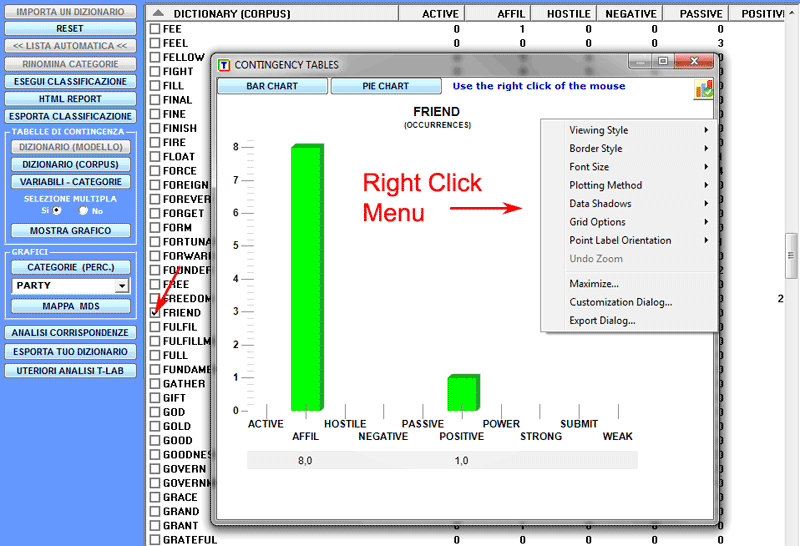
Per realizzare grafici con più serie di dati
corrispondenti a più righe delle tabelle di contingenza, basta
scegliere 'Selezione multipla' (opzione 'Si'), selezionare fino a
20 elementi e cliccare il pulsante 'Mostra Grafico' (vedi
sotto).
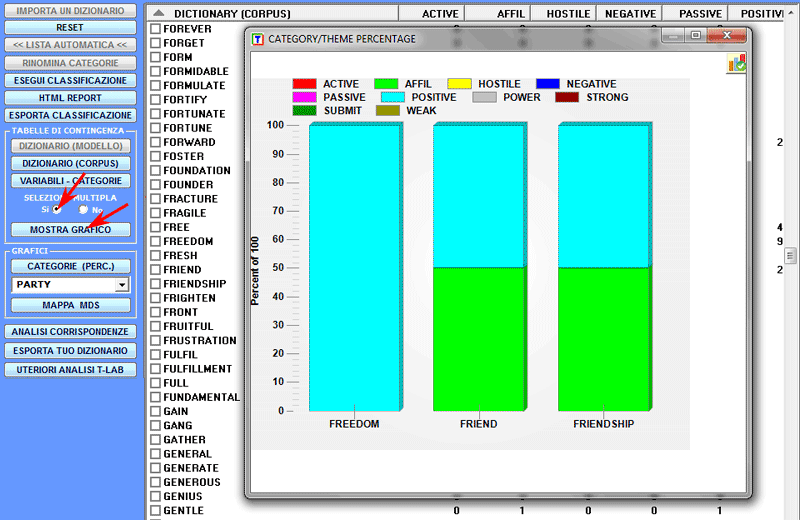
Le due opzioni di cui sopra sono anche disponibili per le
tabelle con i valori delle variabili.
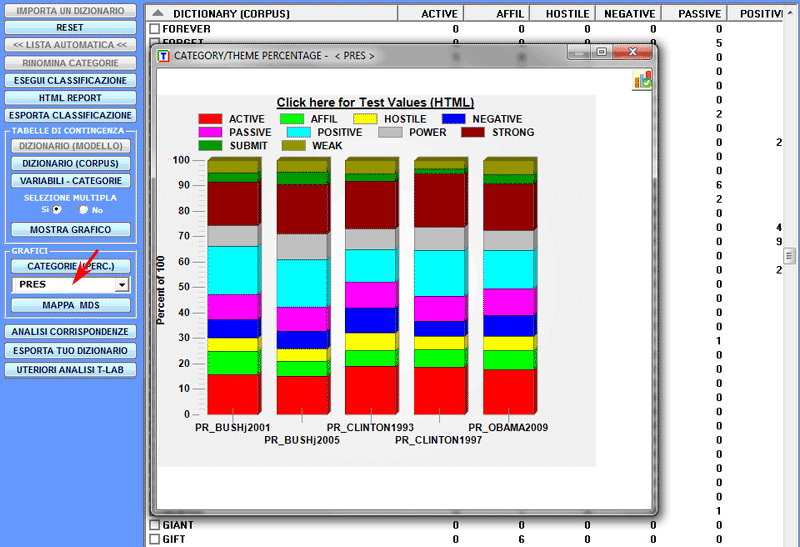
Le percentuali delle categorie possono essere verificate in vari
modi (vedi sotto)
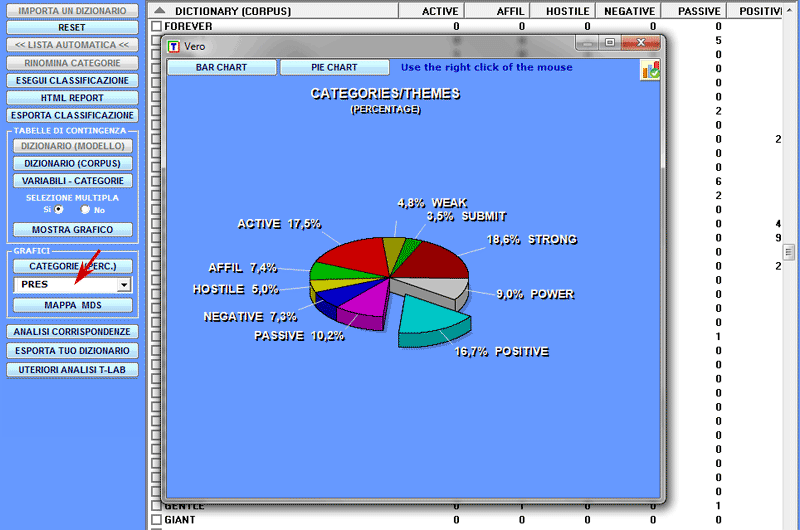
Per esplorare la struttura complessiva dei dati riportati
nelle tabelle di contingenza è possibile utilizzare sia l'opzione
'MDS' che l'opzione 'Analisi delle Corrispondenze' (vedi
sotto).
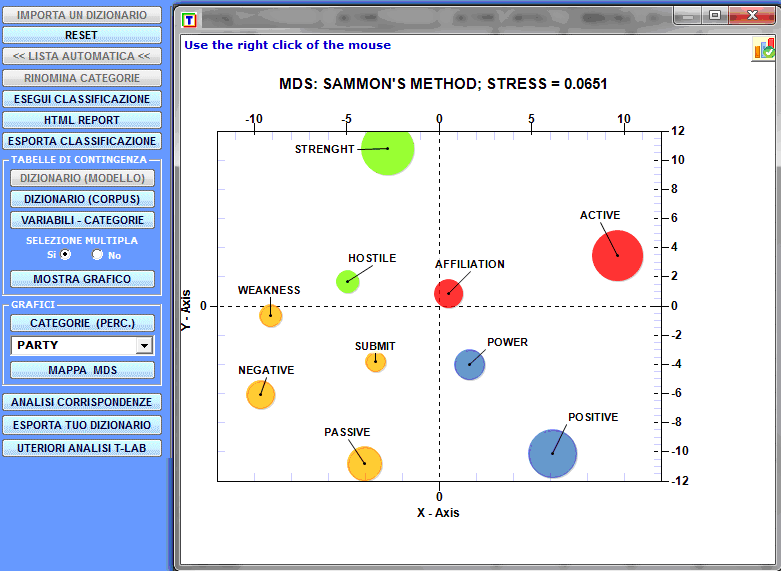
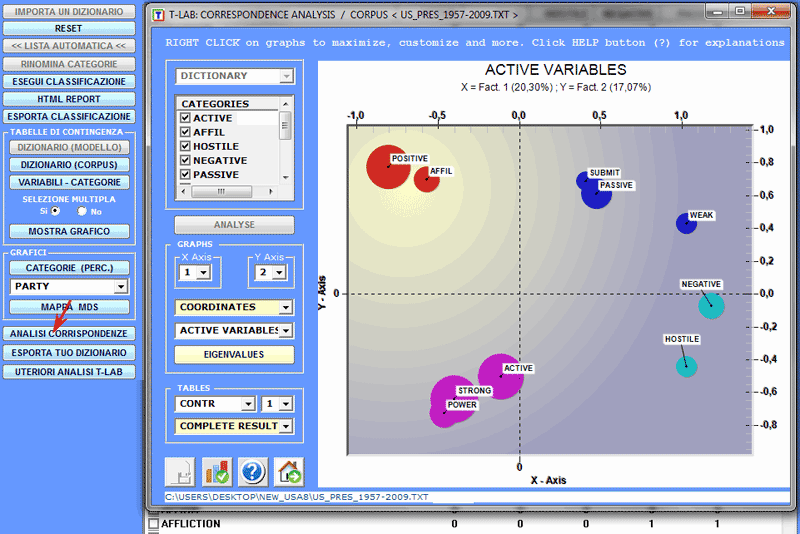
Solo nel caso in cui siano state classificate unità di
contesto è possibile visualizzare ed esportare ulteriori output con
i dati corrispondenti; inoltre, in tal caso, è anche possibile
salvare i risultati dell'analisi in una nuova variabile e
proseguire l'esplorazione con altri strumenti del menu
T-LAB.
In dettaglio, cliccando sul pulsante 'HTML Report' è possibile
visualizzare alcuni risultati del processo di classificazione in
cui un punteggio di somiglianza (Coseno) è assegnato a tutti i
'contesti elementari' o 'documenti' appartenenti alle varie
categorie (N.B.: le immagini che seguono sono relative un corpus di
documenti contenenti brevi descrizioni di aziende).
 . .
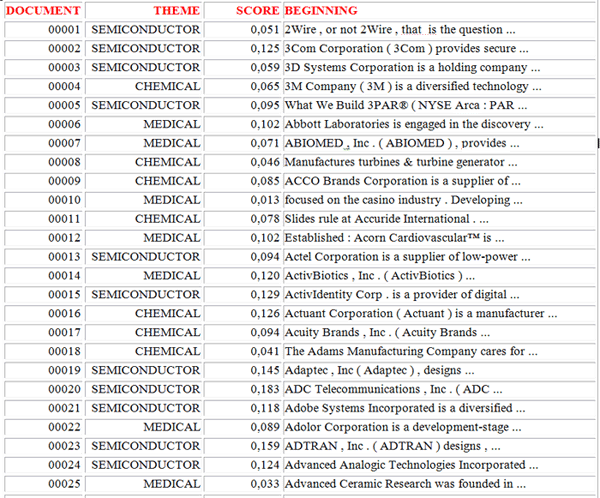
Dati analoghi possono essere esportati in file XLS (vedi
sotto) che contengono tutte le informazioni riguardanti i contesti
elementari ('Context_Classification.xls') o i documenti
('Document_Classification.xls') correttamente classificati;
(1) - Context_Classification.xls
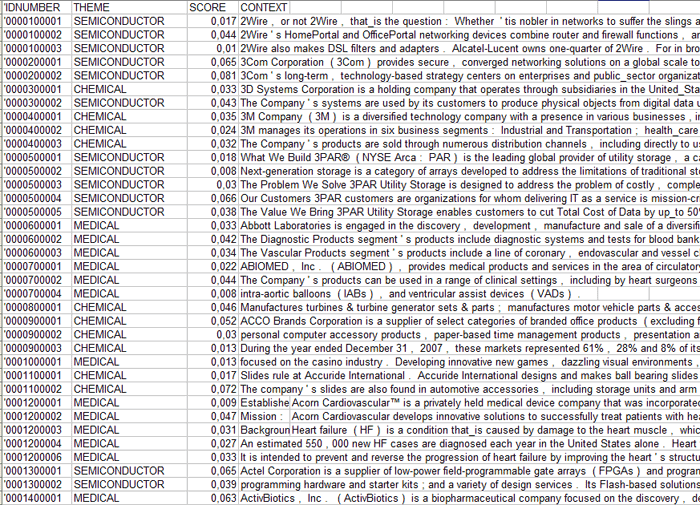
(2) - Document_Classification.xls
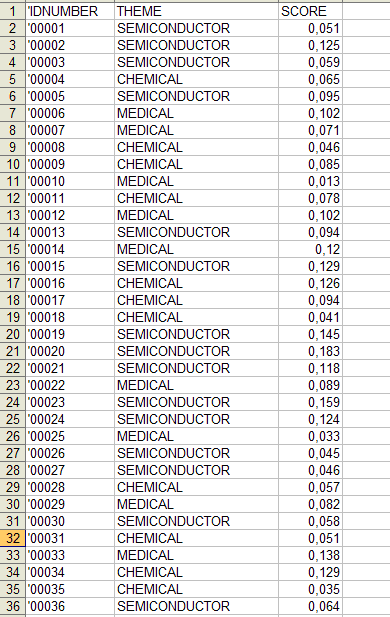
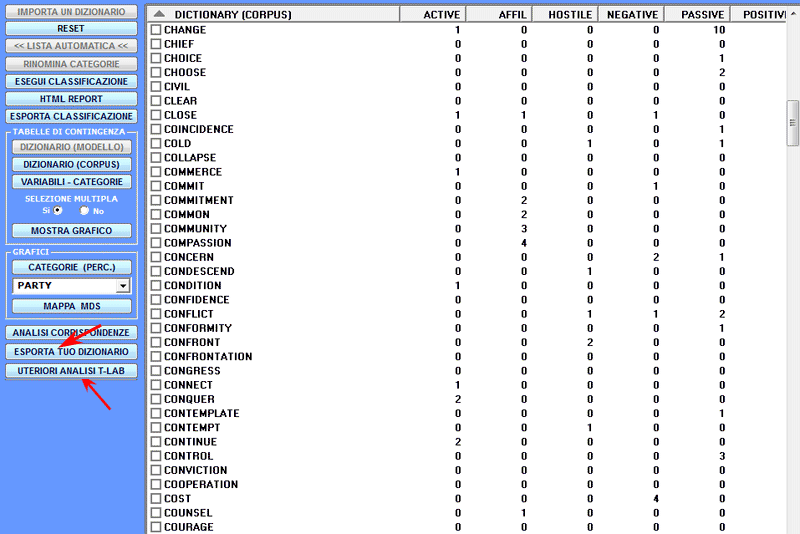
D) - ULTERIORI FASI DEL PROCESSO DI ANALISI
Quando il processo di classificazione ha prodotto i suoi
output, sono disponibili due ulteriori opzioni:
- 'Esporta il tuo Dizionario', che crea un dizionario
pronto per essere importato e utilizzato con altri strumenti
T-LAB per le analisi
tematiche;
- 'Ulteriori analisi T-LAB ', che, a seconda della
struttura del corpus analizzato, del tipo di classificazione
eseguita e del numero di categorie applicate, produce una nuova
variabile che può essere utilizzata da altri strumenti T-LAB (vedi sotto).
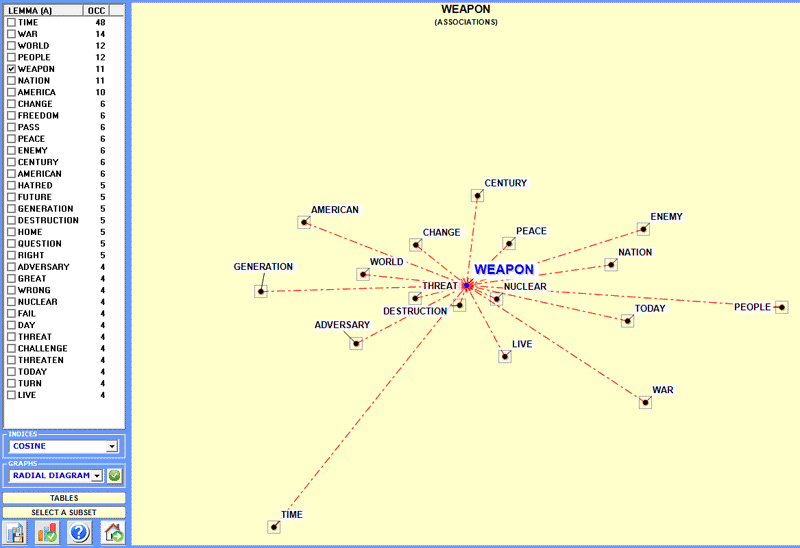
Di seguito è riportato un esempio ottenuto analizzando un
'sottoinsieme' dei contesti classificati mediante lo strumento
Associazioni di Parole (vedi il menu
principale T-LAB).
E) - FORMATO INPUT/OUTPUT DEI DIZIONARI T-LAB
Di seguito vengono riportate tutte le informazioni sul formato dei dizionari che possono essere importati
da questo strumento T-LAB.
- tutti i dizionari devono essere file testo (ASCII/ANSI)
con estensione 'dictio.' (e.s.: Mycategories.dictio);
- tutti i dizionari creati da strumenti T-LAB per le analisi tematiche, inclusi quelli
creati dallo strumento 'Classificazione Basata su Dizionari', sono
pronti per essere importati senza ulteriori interventi da parte
dell'utilizzatore;
- altri dizionari, sia essi 'standard' che personalizzati devono
essere prodotti seguendo le indicazioni riportate di
seguito:
1 - ciascun dizionario è costituito da 'n' righe e non può superare
il limite di 100.000 record;
2 - ogni
riga del dizionario include due o tre 'stringhe' separate dal segno
di punto e virgola (ad es.: economico; credito);
3 - per ogni linea, la prima stringa deve essere una
'categoria', la seconda una 'parola' (o lemma), la terza - se
presente - deve essere un numero reale positivo (cioè un numero
intero) da '1' a '999' che rappresenta il 'peso' di ogni parola
all'interno della categoria corrispondente;
4 - la
lunghezza massima di una stringa (parola, lemma o categoria) è di
50 caratteri e non deve contenere né gli spazi vuoti né
apostrofi;
5 - quando il dizionario include
multi-words (es. Governo Federale), gli spazi vuoti devono essere
sostituiti con il carattere '_' (es. Governo_Federale);
6 - in ogni dizionario, il numero delle categorie
utilizzate possono variare da un minimo di 2 a un massimo di 50.
Quando il numero di categorie è superiore a 50 si consiglia di
utilizzare un dizionario di formato diverso e di importarlo tramite
lo strumento Personalizzazione del
Dizionario (vedi 'Strumenti Lessico' nel menu T-LAB). In tal
caso si ricorda che ogni parola deve essere in corrispondenza
univoca con una (sola) categoria.
Di seguito sono riportati due estratti di file .dictio,
rispettivamente con due e tre stringhe per riga.
a) caso con due stringhe (vale a dire 'coppie' di
categorie e parole)
...
negativo;catastrofico
negativo;nocivo
...
positivo;fantastico
positivo;soddisfatto
...
b) caso con tre stringhe (cioè categorie, parole e
numeri)
...
negativo;catastrofico;10
negativo;nocivo;8
...
positivo;fantastico;9
positivo;soddisfatto;7
|


