|
www.tlab.it
Lemmatizzazione
Nei dizionari linguistici che consultiamo, ogni
voce corrisponde a un lemma che -
generalmente - definisce un insieme di parole con la stessa radice
lessicale (o lessema) e che appartengono alla stessa categoria
grammaticale (verbo, aggettivo, etc.).
Di norma, la lemmatizzazione comporta
che le forme dei verbi vengono ricondotte all'infinito presente,
quelle dei sostantivi e degli aggettivi al maschile singolare,
quelle delle preposizioni articolate alla loro forma senza
articolo, e così via.
Ad esempio, le forme flesse "parliamo"
e "parlato", risultanti dalla combinazione di un'unica radice (<parl->) con due diversi suffissi
(<-iamo> <-ato>), sono ricondotte allo stesso lemma
"parlare".
Si danno tuttavia dei casi in cui la lemmatizzazione non segue la
regola della radice comune; in particolare, nella categoria dei
verbi irregolari. Ad esempio, "vado" e "andremo" sono entrambe
forme del lemma "andare".
Nella fase di importazione del corpus, T-LAB consente di effettuare un particolare
tipo di lemmatizzazione automatica che segue la logica del seguente
"albero".
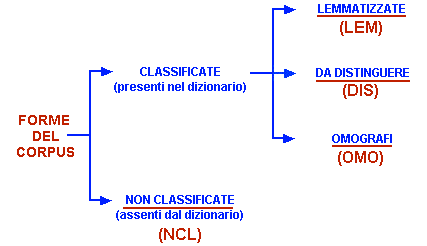
Ovviamente, il dizionario di riferimento è quello
implementato in T-LAB.
Le sigle delle quattro categorie sono utilizzate in
molte tabelle, sempre nella colonna (o campo) "INF".
N.B.:
-, la categoria "DIS" ("da distinguere") è
costituita dai casi in cui T-LAB
riconosce parole - in generale, nomi e aggettivi - per le quali è
opportuno non applicare la lemmatizzazione standard; ciò per
evitare che vengano appiattite le differenze tra i diversi
significati delle forme singolari e plurali (ad es. "beni" e
"bene", "culture" e "cultura"), oppure delle forme femminili e
maschili ("singola" e "singolo", "tecnica" e "tecnico");
- a volte, per marcare casi di
omografia, T-LAB aggiunge il carattere
('_') a uno dei lemmi corrispondenti.
|


