|
www.tlab.it
Modelización de Temas
Emergentes
Este instrumento T-LAB
permite individualizar, analizar y modelizar
los principales temas que emergen de los textos y,
consecuentemente, utilizarlos en ulteriores análisis, tanto de tipo
cualitativo como de tipo cuantitativo.
Los temas emergentes - que están descritos a través
de sus vocabulario característico, es decir a través de un conjunto
de palabras clave que se presentan en coocurrencia en las unidades de contextos
examinados - pueden ser utilizados para clasificar estas unidades (tanto documentos como
contextos elementales) y obtener nuevas variables utilizables en
nuevas análisis T-LAB.

Un cuadro de diálogo T-LAB
(véase arriba) permite que el usuario fije dos parámetros de
análisis.
En particular:
- el parámetro (A) permite establecer el número de temas que se
obtendrán. (Tenga en cuenta que cuanto mayor sea este número, más
coherentes serán las relaciones de co-ocurrencia dentro de cada
tema, y si es necesario, algunos temas - por ejemplo, los que son
redundantes o difíciles de interpretar - pueden ser eliminados en
un segundo momento a través de una funcionalidad específica del
instrumento en examen);
- el parámetro (B) permite excluir del análisis cualquier unidad de
contexto que no contenga un número mínimo de palabras clave
incluidas en la lista utilizada.
Solo cuando usted elija personalizar todos los parámetros de
análisis (véase la opción 'Sí' arriba), se mostrará la ventana
siguiente y habrá más opciones disponibles. (Tenga en cuenta que en
la siguiente imagen el número de unidades de contexto está
determinado por el parámetro "B" mencionado
anteriormente).

El proceso automático de
análisis sigue los siguientes pasos:
a - construcción de una matriz documentos por palabras, donde los
documentos son siempre contextos elementales que corresponden a las
unidades de contexto (es decir, fragmentos, frases, párrafos) en
los que se ha subdividido el corpus;
b - análisis de datos a través un modelo probabilístico que usa la
Latent Dirichlet Allocation y el Gibbs Sampling (para más
información se pueden consultar las siguientes Web de Wikipedia:
http://en.wikipedia.org/wiki/Latent_Dirichlet_allocation;
http://en.wikipedia.org/wiki/Gibbs_sampling;
c - descripción de cada tema a través de los valores de
probabilidades asociados a sus palabras características, tanto
"específicas" como "compartidas" por uno o más temas.
Al final del proceso de análisis, el usuario puede
fácilmente efectuar las siguientes operaciones:
1 - explorar las características de cada tema;
2 - explorar las relaciones entre los diversos
temas;
3 - renombrar o eliminar temas específicos;
4- verificar la coherencia semántica entre los diferentes
temas;
5 - probar el modelo y asignar los temas a las unidades
del contexto, tanto documentos como contextos elementales;
6 - aplicar el modelo y crear una nueva variable
temática,cuyos valores son los temas elegidos;
7 - exportar un diccionario de las categorías, que se
puede utilizar en un análisis posterior.
En el detalle:
1 - Explorar las características de cada
tema
El primer resultado que se puede consultar y guardar
consiste en una tabla con una Vista
previa de todos los temas. Y, cuando se desee, se puede
volver a acceder fácilmente utilizando el botón correspondiente
(ver a a continuación).

Además se puede acceder a otros tipos de resultados
eligiendo una de las opciones resaltadas en la imagen
siguiente.

NOTA: En este gráfico "hight probability" indica una
probabilidad >=.75.
Cuando se selecciona un tema, al hacer clic en la opción
"Tabla Theme", se pueden verificar sus características; además, al
hacer clic en cualquier palabra de la tabla que se muestra, parece
una opción adicional que permite "eliminar" el elemento seleccionado (ver imagen a
continuación).

Las claves de lectura de la tabla anterior son las
siguientes:
IN THEME = ocurrencias (tokens) de cada palabra dentro del tema
seleccionado;
TOT = ocurrencias (tokens) de cada palabra dentro del corpus o del
subconjunto analizado;
IN (%) = peso porcentaje de cada palabra dentro del tema
seleccionado;
(p) = valor de probabilidad asociado a cada relación palabra x
tema;
TYPE = marcado como "specific" cuando
la palabra (con p = 1) pertenece solo al tema seleccionado y como
"shared" en todos los otros casos (es
decir cuando la palabra es presente, en maneras diferentes, en mas
de un tema).
Cuando se selecciona un tema, al hacer clic en la opción
"Mapa MDS" se pueden explorar
fácilmente las relaciones semánticas entre las palabras que son más
características (ver la imagen siguiente).

Además, utilizando la herramienta 'Graph Maker', algunas opciones gráficas
adicionales están disponibles (ver las imágenes siguientes).


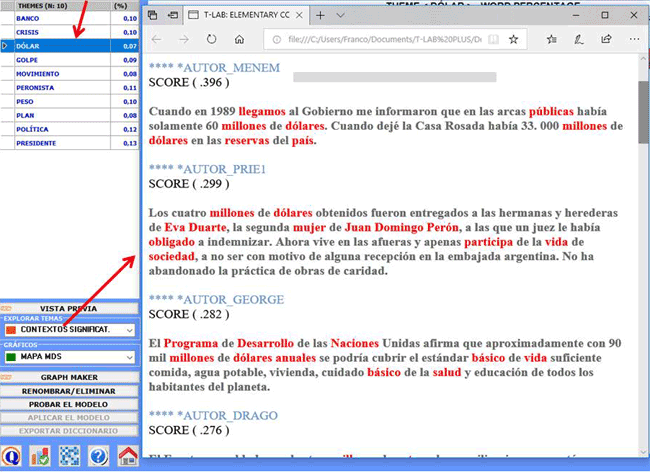
Cuando se selecciona un tema, al hacer clic en la opción
"contextos significativos", se crea un archivo HTML donde se
muestran los 20 segmentos de texto principales, que se corresponden
más con las características del tema (ver la imagen
siguiente).
2 - Explorar las relaciones entre los
diversos temas
Usando la herramienta Análisis de
Correspondencia se pueden crear y explorar dos tipos de tablas
de contingencia:
2.1) una tabla palabras por tema (ver abajo)

2.2) una tabla que cruza los temas con las modalidades de
la variable seleccionada

También hay otras dos opciones gráficas disponibles que
nos permiten mapear las relaciones entre los diversos temas:
2.3) un mapa MDS

2.4) un gráfico de red obtenido al exportar / importar la
tabla de adyacencia creada por T-LAB
(ver a continuación)


NOTA: El gráfico anterior se ha creado por medio del
programa Gephi (https://gephi.org/ ), después haber importado una
tabla creada por T-LAB.
3 - Renombrar o eliminar
temas
Para renombrar o eliminar temas específicos es suficiente
seleccionar los ítems correspondientes (ver "A" en el cuadro
siguiente) y pinchar sobre el botón "renombrar/eliminar" (ver "B" en el cuadro
siguiente).
Cuando aparece el cuadro con las varias opciones, el usuario puede,
según su objetivos, cambiar la etiqueta del tema (tanto eligiendo
entre las palabras disponibles como tecleando una nueva palabra;
ver "C" en el cuadro siguiente) o eliminar el tema seleccionado
pinchando sobre el botón correspondiente (ver "D" en el cuadro
siguiente).

4 - Verificar la coherencia semántica
entre los diferentes temas

Al hacer clic sobre el icono 'Índices de Calidad' (véase arriba),
T-LAB calcula las semejanzas
entre las primeras 10 palabras características de cada tema (top
10).
Más en concreto:
- Las primeras 10 palabras son aquellas caracterizadas por un valor
de probabilidad más alto
- las medidas de semejanza están calculadas con base en el
coeficiente del coseno;
- Al igual que para la herramienta Asociación de Palabras, el coeficiente del
coseno se calcula verificando las co-ocurrencias de las palabras
contenidas en los segmentos de texto definidos como contextos
elementales.
Come resultado, T-LAB genera un
archivo HTML en el cual los 'k' temas están recogidos en un listado
y van asociados a sus respectivos índices de 'coherencia
semántica'.
NOTA: Las medidas de semejanza varían en función de los cambios en
las palabras seleccionadas. Por ello, se recomienda repetir el
procedimiento cada vez que alguna de las diez palabras asociadas a
un tema haya sido eliminada por el usuario.
5 - Probar el modelo y
asignar los temas a las unidades del contexto
Al final del análisis de los datos (ver los puntos "a" y "b" del
proceso de análisis) cada unidad de contexto (por ejemplo un
documento o un contexto elemental) resulta constituido como una
mixtura de temas. De otra manera, el proceso de clasificación
utilizado para probar/aplicar el modelo asocia cada unidad de
contexto al tema que mas lo caracteriza. Como resultado, en esta
fase, cada tema se pone de hecho como un clúster de unidad de
contexto.
Por esa razón, cuando se selecciona la opción "Probar el
Modelo", T-LAB
produce dos archivos XLS (ver abajo) que permiten a el usuario de
verificar la pertenencia de cada unidad de contexto a un tema
específico.

NOTA: En la tabla anterior cada documento tiene un valor
de probabilidad asociado con cada tema.

6 - Aplicar el modelo
Después haber aplicado y
guardado el modelo, por tanto que los temas son archivados por
T-LAB
como modalidades de dos nuevas variables que se refieren a clúster
de contextos elementales (CONT_CLUST)
y/o a clúster de documentos (DOC_CLUST), las relaciones entre los mismos temas
y/o sus características pueden ser más explorados con diferentes
instrumentos de análisis (ver el cuadro siguiente).

Por ejemplo, usando la herramienta Asociaciones de palabras y seleccionando el
subconjunto (es decir, el tema) "Dólar", se puede crear el
siguiente gráfico.

7 - Exportar un diccionario de
las categorías modelo
Cuando se selecciona esta opción, T-LAB
genera un archivo diccionario con extensión .dictio listo para ser importado a través de una de
las herramientas disponibles para el análisis temático. En dicho
diccionario, cada categoría viene descrita a través de sus palabras
características.
|


