Exploring US Presidential Inaugural Addresses
A piece of whimsy about text and context (7 February 2009. The version of T-LAB used was T-LAB 6.1)
NOTICE:
The following example has been realized by using
an old version of T-LAB (6.1). The latest version (T-LAB
8.0) includes new tools and a new charting system. Click
here to find out more.
On
the
20th January 2009
many millions the world over watched and listened to the Inaugural
Address of Barack Obama, 44th President of the United States, and discussed
its likely significance afterwards with friends and neighbours, colleagues,
bartenders or taxi-drivers. Perhaps never in the history of mankind have a few
words received the immediate attention, scrutiny even, of so many.
Similarly
in a small town in southern Italy Colin (a former
academic linguist) and Franco (the creator of T-LAB)
chatted about Obama's address over a glass or two of good red wine. In the course
of the evening's conversation Colin (somewhat sceptically)
laid down a challenge, as if in vino veritas:
OK,
Franco, so T-LAB is all about automating text analysis. Tell me, is your software
actually up to the task of analysing Obama's speech and deriving from it something
really interesting which no mere mortal has been able to come up with?
Placing
his glass down slowly on the table, and taking a puff of his pipe, Franco
stroked his now greying beard and replied:
Well,
T-LAB isn't magic. It uses a set of statistically based algorithms and, alas,
Obama's speech is too short (at barely four pages) to analyse. But if you like
we can though play about with the similarities and differences between this
speech of his and other speeches. Now
in reality it is impossible to comment on a text without referring to some wider
context. For example, Obama's speech can be analysed and discussed in terms
of an almost limitless number of different contexts like other speeches he himself
has made, recent speeches of other Heads of State, … (pause)…
Colin:
Er, yes … and?
Franco:
How about we look at his address in the context of
the inaugural addresses of other presidents of the United States?
This,
then, is the story of what happened as a result of the conversation of these
two friends. It is an account of what playing about with T-LAB for no more than
a couple of hours can lead to…
Starting
from Words ...
Franco and Colin decided
to focus their attention on the inaugural addresses of all US
presidents since the Second World War. Since Eisenhower, in fact.
In
less than half an hour - thanks to the internet - the corpus of texts they had
decided on had been assembled and was ready for analysis: fourteen addresses
in all, each one coded by year, name of President, and his (never her) political
affiliation [1]. T-LAB Pro 6.1
is sufficiently powerful that it allowed many alternative analyses. In this
case they chose to take a straightforward, readily replicable, path from words
to themes.
As
far as the software is concerned, if truth be known, words are simply strings
to be recognised, classified, and counted. Nevertheless certain leads seemed
particularly interesting.
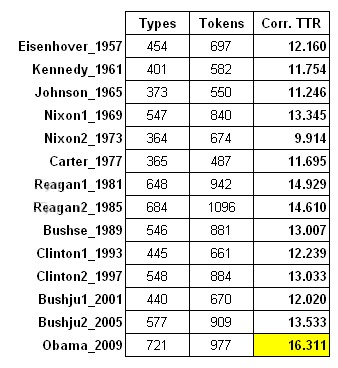
Obama's
speech, compared to others' inaugurals is (perhaps unsurprisingly, but worth
noting) characterised by a more raised level of lexical
richness. (See the Corpus
Vocabulary tool). In fact this indicator can be computed in two ways in
particular: by examining the ratio between word types (that is, the number of
'distinct words') and word tokens (the total number of occurrences of words
in the text), or by applying a factor which corrects for differing lengths of
text. In the following table we have used corrected type/token
ratios (Corr. TTRs)[2].
Note that in the above table the calculation of types and tokens has been made
taking into consideration only the content words
(i.e. nouns, verbs, adjectives and adverbs).
This
first finding might suggest that Obama's speech is in some way an invitation
to reflect. In fact the more often an orator uses the same words (in which case
his or her type/token ratio is lower) arguably the greater the likelihood that
he or she is using rhetoric designed to win over the audience.
But
which - and this is the big question - are the words which Obama uses which
most characterise his speech? Here again the answer which T-LAB provides is
remarkably simple (See the Specificity
Analysis tool). It involves a straightforward chi
square test applied to a contingency table which cross-tabulates words
against presidential inaugural addresses.
Here
are the first 30 words that the test (df=1; p. 0.05) reveals that Obama "over-uses"
compared to other presidents in their inaugural addresses. To see the first
30 words for all presidents in the corpus click here.
understand
(17.25); job (15.18); storm (13.48); crisis (12.97); common (12.13); hour (10.79);
prosperity (10.79); father (9.69); ambition (8.98); blood (8.98); brave (8.98);
cooperation (8.98); health_care (8.98); humble (8.98); market (8.98); met (8.98);
month (8.98); mutual (8.98); short (8.98); water (8.98); willingness (8.98);
worker (8.98); big (8.79); carry (8.79); woman (8.78); endure (7.40); generation
(8.01); hard (6.50); remain (6.50); business (6.48).
Note:
The same tool (Specificity Analysis -> Exclusive Words) allows us to check
the words used only by Obama (e.g. Muslim,
two times).
A further finding is also potentially interesting. The word that best characterises
Obama's speech is 'understand'. We could easily identify all the contexts in
which Obama has used this term, or the variants 'understood' and 'understanding',
by means of a classical instrument of text analysis (see the Concordances).
But for now our interest is different: beyond the actual words what are the
themes we are invited to think about and try to understand ?
… to Themes
When
qualitative analysts hear that some piece of software is set up to automatically
extract themes from one or more texts they tend to screw up their noses! We
would put to them in turn a simple question: are you in a position to define
exactly what is a 'theme'? T-LAB provides a very precise answer: a theme is
a label which can be attributed to a cluster of context units characterised
by similar co-occurrence patterns. It is then just a matter of determining the
type of contexts to be analysed (sentences in this case) and the word list to
be considered, applying a clustering algorithm, and interpreting the results.
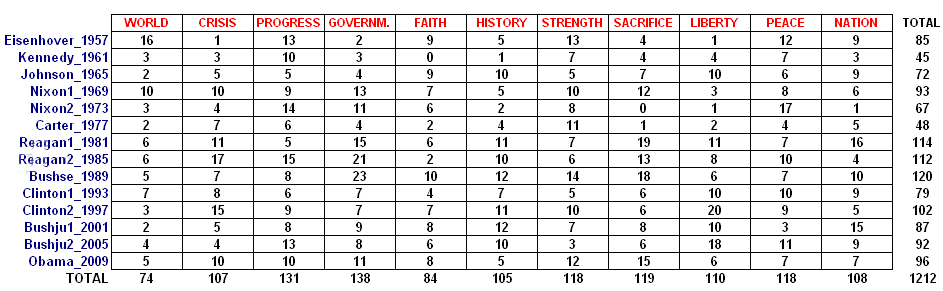
Using
the tool Thematic Analysis of Contexts
T-LAB provides us with eleven thematic clusters. By consulting the output tables
we decided to identify these as follows (where the values in parentheses give
the percentage of the elementary contexts which belong to each thematic cluster).
WORLD
(6.11%); CRISIS (8.83%); PROGRESS (10.81%); GOVERNMENT (11.39%); FAITH (6.93%);
HISTORY (8.66%); STRENGTH (9.74%); SACRIFICE (9.82%); LIBERTY (9.08%); PEACE
(9.74%); NATION (8.91%).
Colin:So
the first interesting finding from T-LAB is that these same eleven themes occur
in every president's inaugural speech.
Another
question: in this case which is the best way of graphically representing the
relationship between the fourteen presidential addresses and the eleven themes
which, in varying percentages, were found in each of them?
Again
T-LAB provides a simple way of dealing with this: save the results of the cluster
analysis and then use the tool Multiple
Correspondence Analysis. Even though the analysed table has two columns
(i.e. presidents and clusters) and as many rows as there are classified elementary
contexts, it can be summarised by a contingency table like the following.
Note: The numerical values indicate how many of the classified contexts of each
presidential speech belong to each of the thematic clusters.
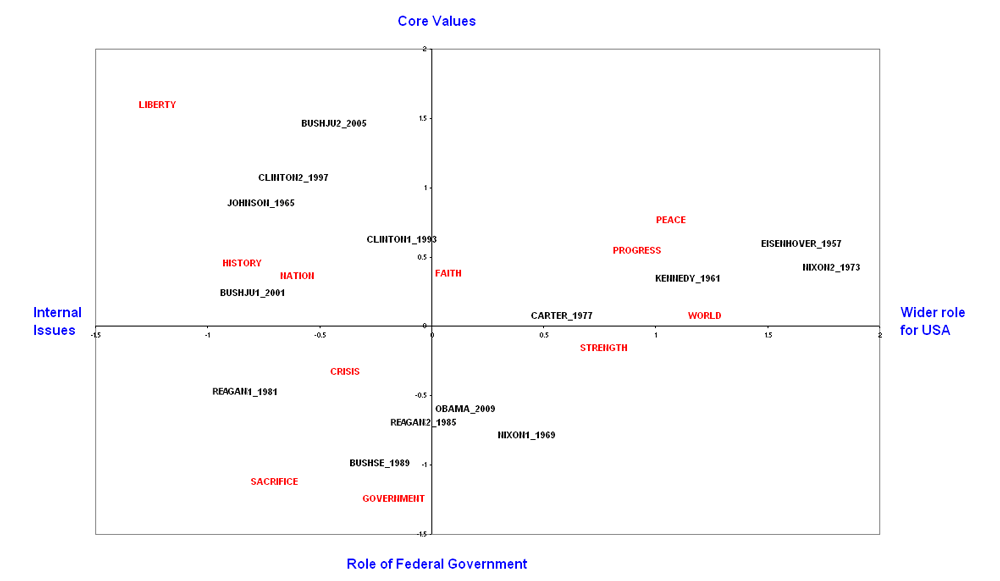
The
associated graph from the multiple correspondence analysis is as follows.
Note that the graph represents the relationship between data points in a two-dimensional
space based on the first two factors extracted. The labels attributed to the
four polarities were decided on after consulting the output tables from T-LAB
giving the characteristic words for each factor.
It
is at this point that something decidedly unexpected emerges from our analysis
of Obama's speech. With respect to its thematic content
Obama's speech has greater similarity to the inaugural addresses of certain
Republican presidents, in particular Reagan's second address and Nixon's first...
Endnote
Colin:
So our two hours are up. Franco, can you just spell out for me how you think
you have answered my original question about whether T-LAB can do things which
mere mortals cannot do?
Franco:
Before I answer your main question let me just comment on the two-hour time
limit. We did of course set this limit just for fun, so we shouldn't necessary
expect to have come up with a full and final analysis of inaugural addresses
within this artificial limitation! If we were doing this for "real"
we would make use of a wide range of T-LAB tools to effect further analyses
and gain a deeper understanding of the relationship between our chosen texts.
This might take a matter of a working day rather than two hours.
Just
as the two-hour time limit was arbitrarily chosen I think, Colin, that you arbitrarily
(and perhaps mischievously) tried to force a choice between T-LAB and human beings. The fact is that T-LAB
needs a user, and moreover one who can make prudent choices between the various
tools available, can evaluate the consequences of different parameter settings,
and - overall - can interpret the meaning of different possible relationships
emerging from the outputs (tables and charts). An intelligent user can then, however,
employ T-LAB to work at a pace and intensity of analysis which no mere mortal
could ever achieve unaided.
1
- There should in fact have been sixteen inaugural addresses but circumstances
were such that two politicians (Lyndon Johnson in 1963, and Gerald Ford in 1974)
did not deliver speeches. See http://janda.org/politxts/index.html
2 - These are obtained, following J.B. Caroll (1964), by
dividing the number of types by the square root of twice the number of tokens.
This website uses cookies so that we can provide you with the best user experience possible. Cookie information is stored in your browser and performs functions such as recognising you when you return to our website and helping our team to understand which sections of the website you find most interesting and useful.
Strictly Necessary Cookies
Strictly Necessary Cookie should be enabled at all times so that we can save your preferences for cookie settings.
If you disable this cookie, we will not be able to save your preferences. This means that every time you visit this website you will need to enable or disable cookies again.
3rd Party Cookies
This website uses Google Analytics to collect anonymous information such as the number of visitors to the site, and the most popular pages.
Keeping this cookie enabled helps us to improve our website.
Please enable Strictly Necessary Cookies first so that we can save your preferences!