|
|
T-LAB 10.2 - ON-LINE HELP |
|
|
www.tlab.it
What T-LAB does and what it enables us to do T-LAB software is an all-in-one set of linguistic, statistical and graphical tools for text analysis which can be used in research fields like Content Analysis, Sentiment Analysis, Semantic Analysis, Thematic Analysis, Text Mining, Perceptual Mapping, Discourse Analysis, Network Text Analysis, Document Clustering, Text Summarization.
In fact T-LAB tools allow the user to easily manage tasks like the following: - measure, explore and map the co-occurrence relationships between key-terms; The T-LAB user
interface is very user-friendly and
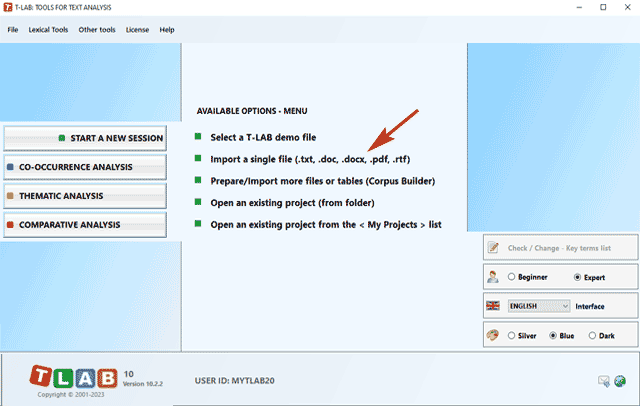
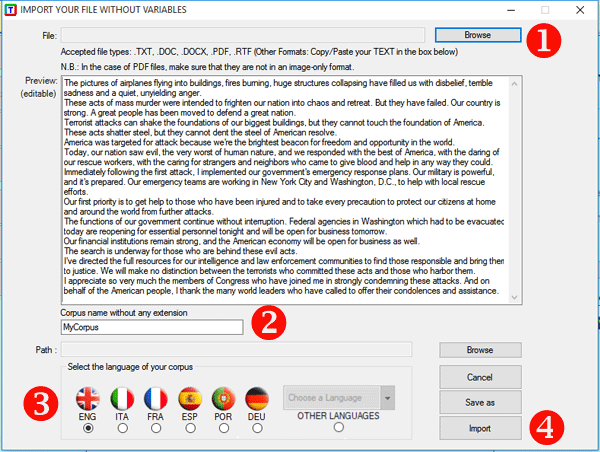
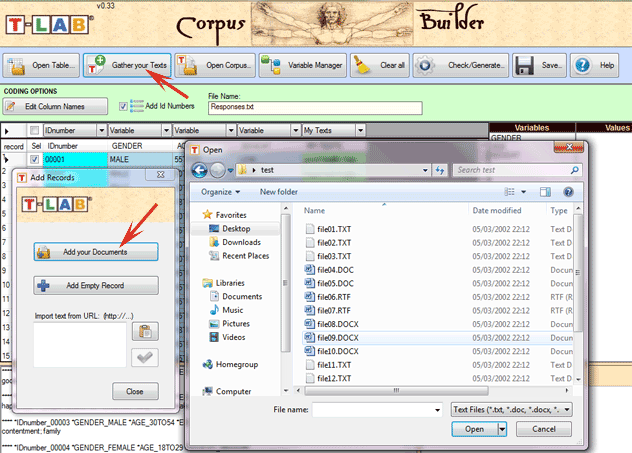
various types of texts can be analysed: All texts can be encoded with categorical variables and/or with Unique Identifiers that correspond to context units or cases (e.g. responses to open-ended questions). In the case of a single document (or a corpus considered as a single text) T-LAB needs no further work: just select the 'Import a single file...' option (see below) and proceed as follows.
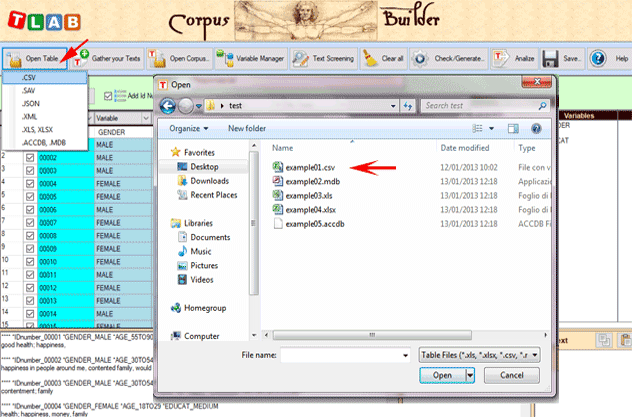
When, on the other hand, the corpus is made up of various texts and/or categorical variables are used, the Corpus Builder tool (see below) must be used. In fact, such a tool automatically transforms any textual material and various types of files (i.e. up to eleven different formats) into a corpus file ready to be imported by T-LAB.
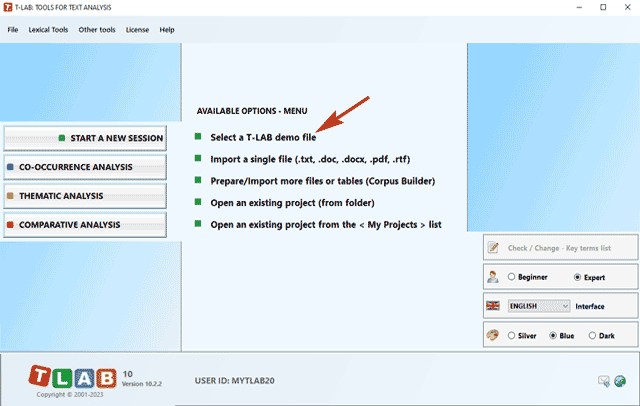
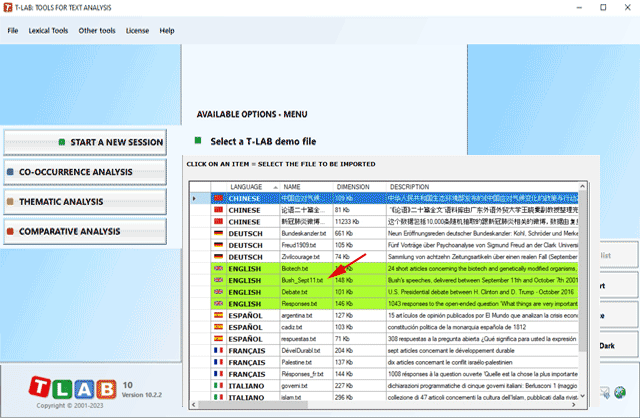
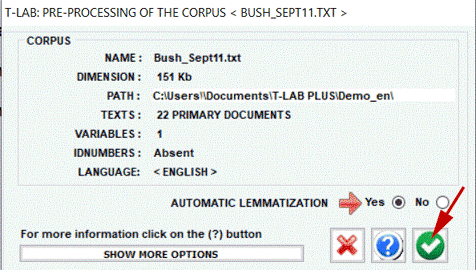
N.B.: At the moment, in order to ensure the integrated use of various tools, each corpus file shouldn't exceed 90 Mb (i.e. about 55,000 pages in .txt format). For more information, see the Requirements and Performances section of the Help/Manual. Six steps are that is required to perform a quick verification of the software functionalities: 1 - Click on the 'Select a T-LAB demo file' option
2 - Select any corpus to analyse
3 - Click "ok" in the first Setup window
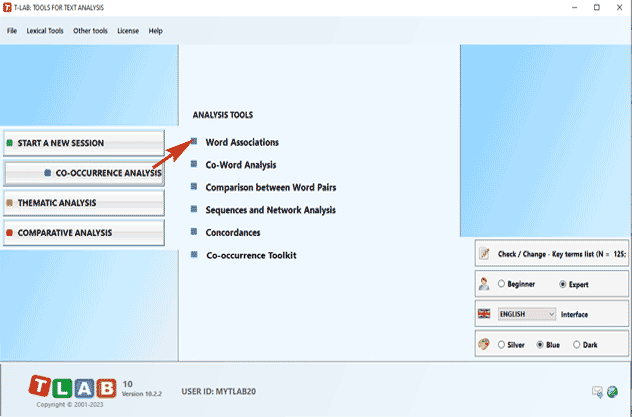
4 - Select a tool from one of the "Analysis" sub-menus
5 - Check the results
6 - Use the contextual help function to interpret the various graphs and tables
From an external point of view, the use of the software is organized from the interface, that is from the main menu, from the sub-menus and from the options that they consist of. Apart from the user interface, the T-LAB system is organized into two main components:
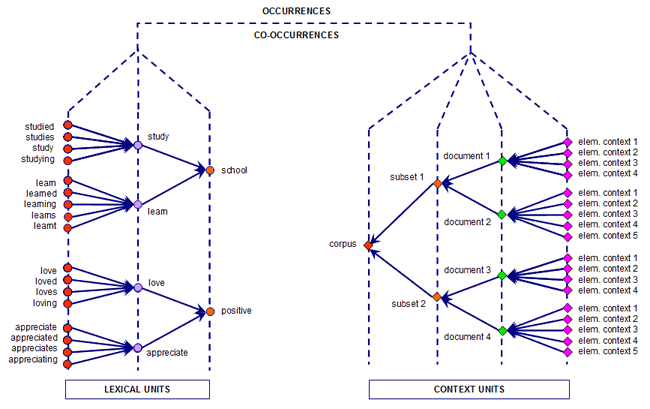
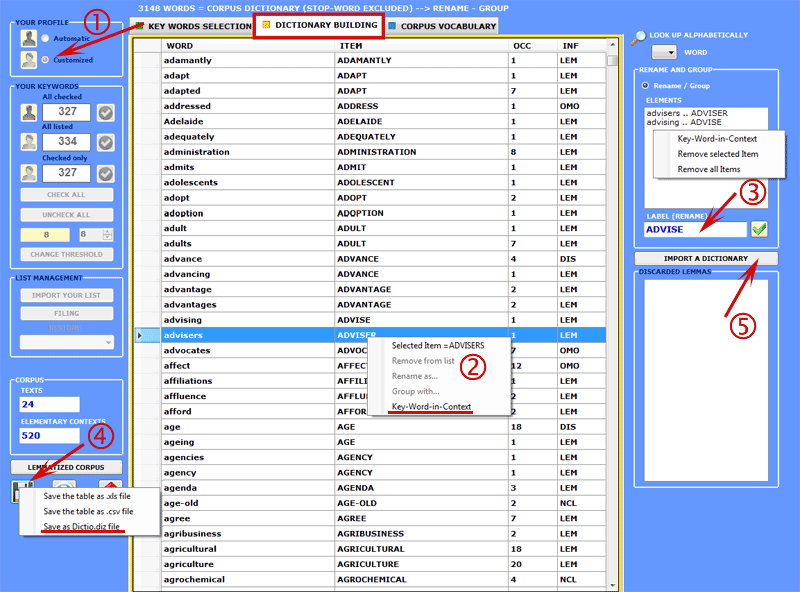
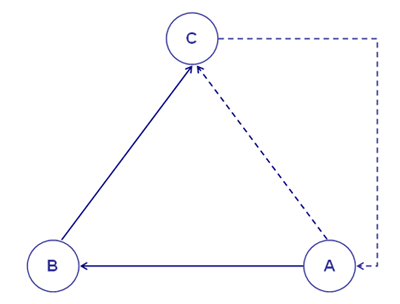
To understand how T-LAB works and how it can be used, it is essential to have a clear idea as to which analysis units are filed in its database and what statistical algorithms are used in the various analyses. In fact, the analysed data tables always consist of rows and columns the headings of which correspond to the analysis units filed in the database, while the algorithms regulate the processes that make it possible to detect significant relationships between the data and to extract useful information. The analysis units used in T-LAB are of two types: lexical units and context units. A - the lexical units are words and multi-words, filed and classified on the basis of a criterion. More precisely, in the T-LAB database each lexical unit consists of a classified record with two fields: word and lemma. In the first field ("word"), the words are listed as they appear in the corpus, while in the second ("lemma") the labels attributed to groups of lexical units are listed and classified according to linguistic criteria (e.g. lemmatization) or by dictionaries and semantic grids defined by the user. B - the context units are portions of text that the corpus can be divided into. More precisely, according to T-LAB logic, there can be three types of context units: B.1 primary documents, which
correspond to the "natural" subdivision of the corpus (e.g.
interviews, articles, answers to open-ended questions, etc.), that
is the initial context defined by the
user; The picture below illustrates the possible relationships between lexical and context units which T-LAB, through statistical and graphical tools (see section 5 below), allows us to analyse.
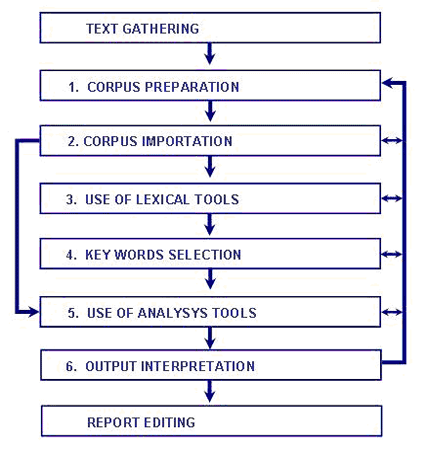
In T-LAB, the selection of any analysis tool (click of the mouse) always activates a semi-automatic process that, with a few simple operations, generates an input table, it applies some statistical algorithms and produces some outputs. Let's
consider how a typical work project
which uses T-LAB can be
managed. The succession of the various phases is illustrated in the following diagram:
Now let's try to comment on the various steps:
In the case of a single text (or a corpus considered as a single text) T-LAB needs no further work. When, on the other hand, the corpus is made up of various texts and/or categorical variables are used, the Corpus Builder tool must be used, which automatically transforms any textual material and various types of files (i.e. up to eleven different formats) into a corpus file ready to be imported by T-LAB. N.B.:
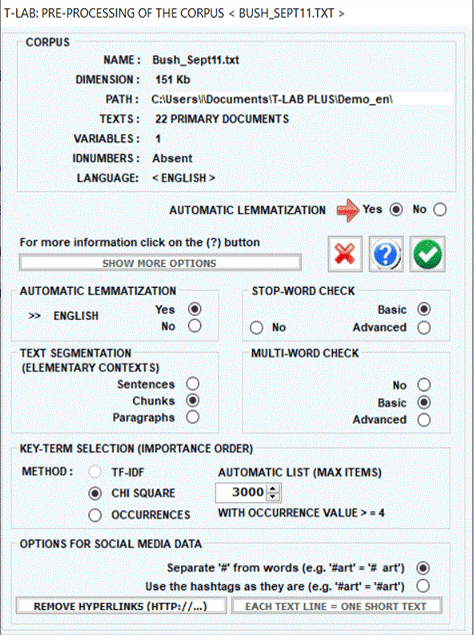
During the pre-processing phase, T-LAB carries out the following treatments:
Here is the complete list of the
languages for which specific pre-processing options are
available. In any case, without automatic lemmatization and / or by using customized dictionaries the user can analyse texts in all languages, provided that words are separated by spaces and / or punctuation.
The setup form in which the user can select the pre-processing options which fit his needs is the following:
The procedures of the various interventions are illustrated in the corresponding help sections (and in the manual). In particular the user is requested to refer to the corresponding help section (and to the manual) for a detailed description of the Dictionary Building process (see below). In fact any change concerning the dictionary entries affects both the occurrence and the co-occurrence computation.
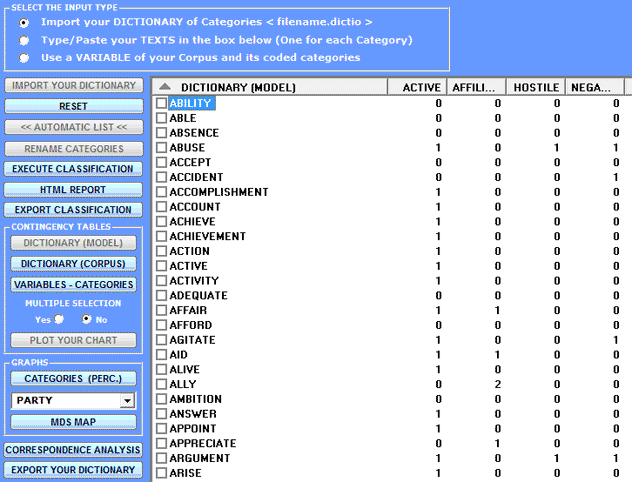
N.B.: When the user, without losing any lexical information, intends to apply coding schemes which group words or lemmas in a few categories (i.e. from 2 to 50) it is advisable to work with the Dictionary-Based Classification tool included in the Thematic Analysis sub-menu (see below).
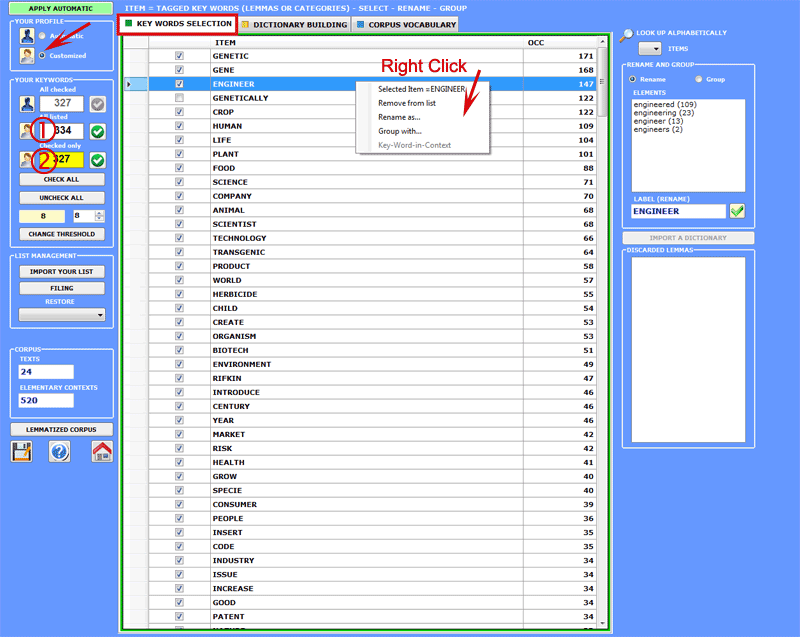
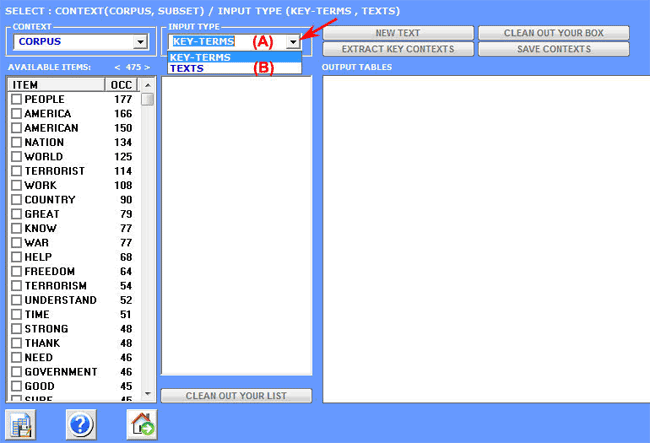
4 - THE KEY-WORD SELECTION consists of the arrangement of one or more lists of lexical units (words, lemmas or categories) to be used for producing the data tables to be analysed. The automatic settings option provides the lists of the key-words selected by T-LAB; nevertheless, since the choice of the analysis units is extremely relevant in relation to subsequent elaborations, the use of customized settings (see below) is highly recommended. In this way the user can choose to modify the list suggested by T-LAB and/or to arrange lists that better correspond to the objectives of his research.
In any case, while creating these lists, the user can refer to the following criteria: - check the quantitative (total of the occurrences) and
qualitative importance of the various
items; 5 -
THE USE OF ANALYSIS TOOLS allow
the user to obtain outputs (tables and graphs) that represent
significant relationships between the
analysis units and enables the user to make inferences.
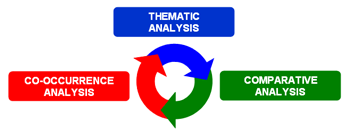
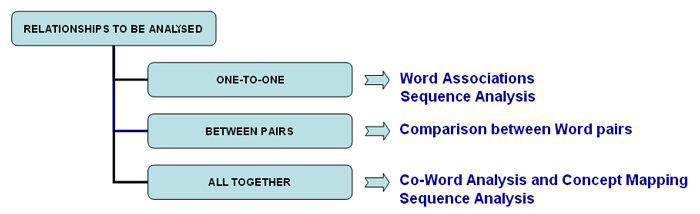
For this purpose, besides the distinction between tools for co-occurrence, comparative and thematic analysis (see below), it can be useful to consider that some of the latter allow us to obtain new units corpus subsets which can be included in further analysis steps. Even though the various T-LAB tools can be used in any order, there are nevertheless three ideal starting points in the system which correspond to the three ANALYSIS sub-menus:
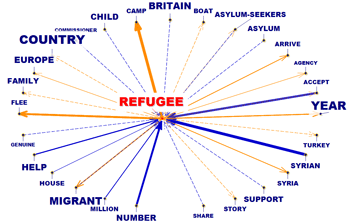
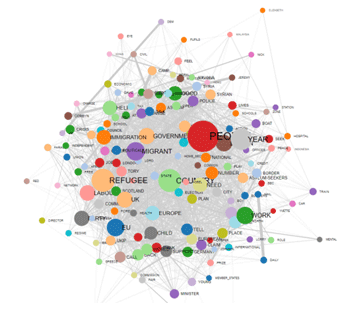
These tools enable us to analyse different kinds of relationships between lexical units (i.e. words or lemmas).
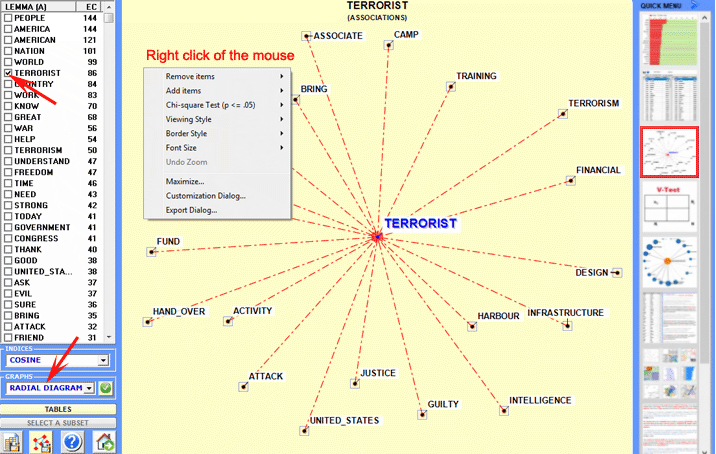
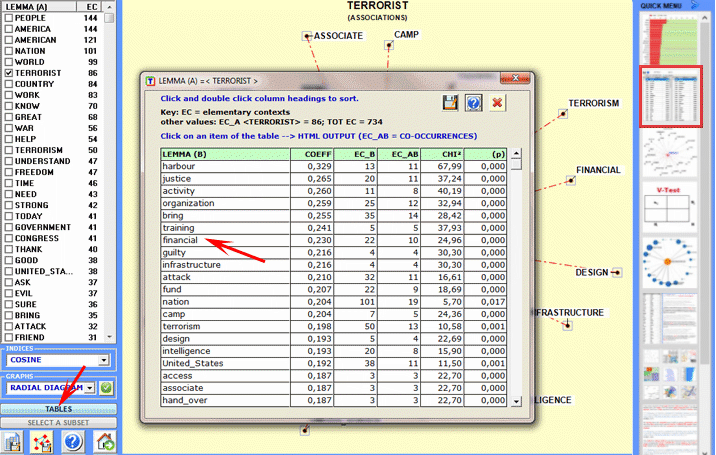
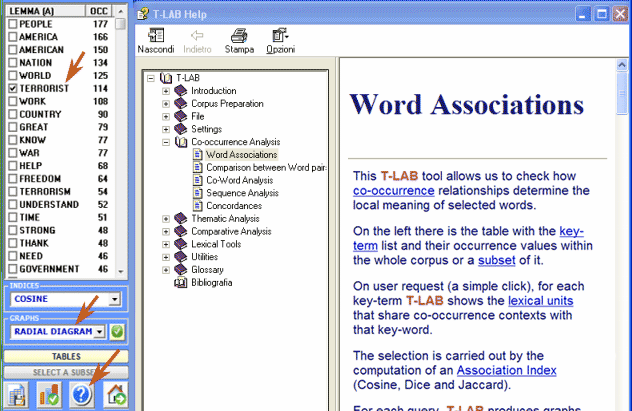
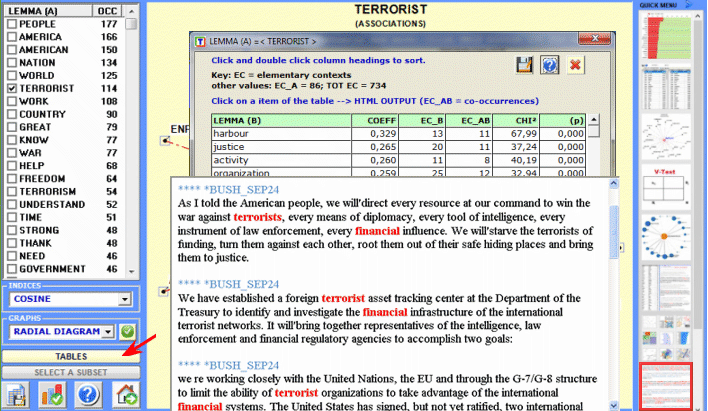
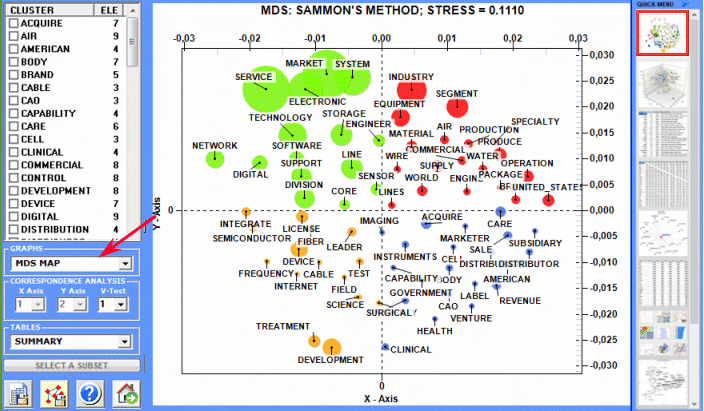
Here are some output examples (N.B.: for more information on how to interpret the outputs please refer to the corresponding sections of the help/manual): This T-LAB tool allows us to check how co-occurrence relationships determine the local meaning of selected word:
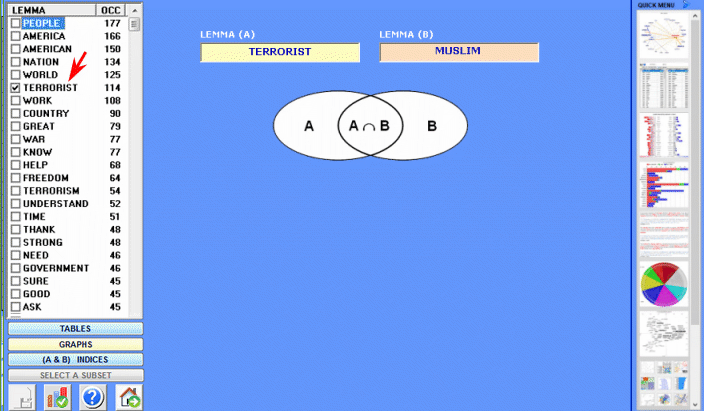
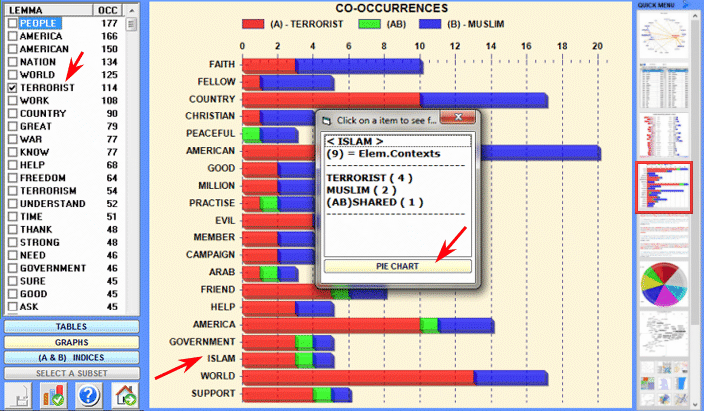
- Comparison between Word Pairs This T-LAB tool allows us to compare sets of elementary contexts (i.e. co-occurrence contexts) in which the elements of a pair of key-words are present:
- Co-Word Analysis and Concept Mapping This T-LAB tool allows us to find and map co-occurrence relationships within (and between) sets of key-words:
This T-LAB tool,
which takes into account the positions of the various lexical units
relative to each other, allows us to represent and explore any text
as a network.
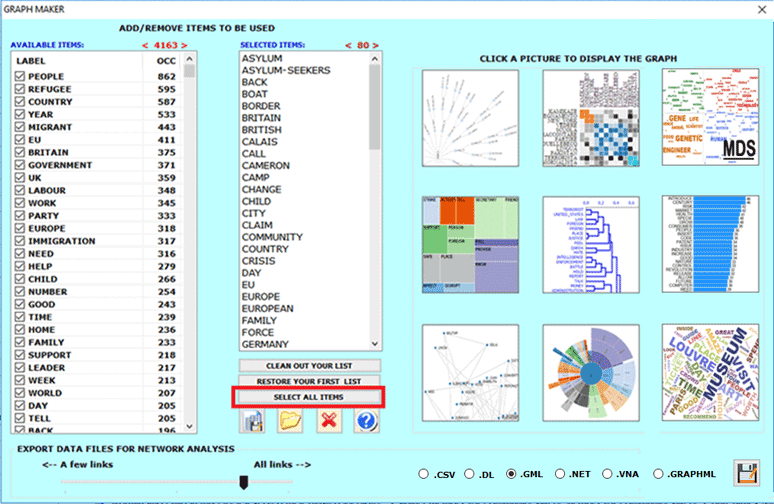
Moreover, by clicking the GRAPH MAKER option, the user is allowed to obtain various types of graphs by using customized lists of key words (see below).
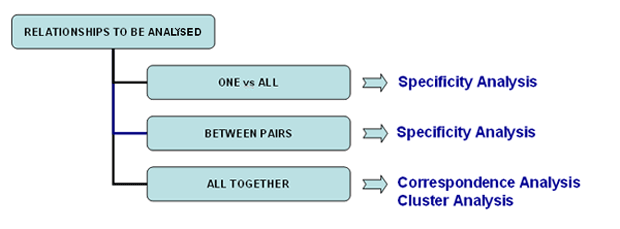
B : TOOLS FOR COMPARATIVE ANALYSIS These tools enable us to analyse different kinds of relationships between context units.
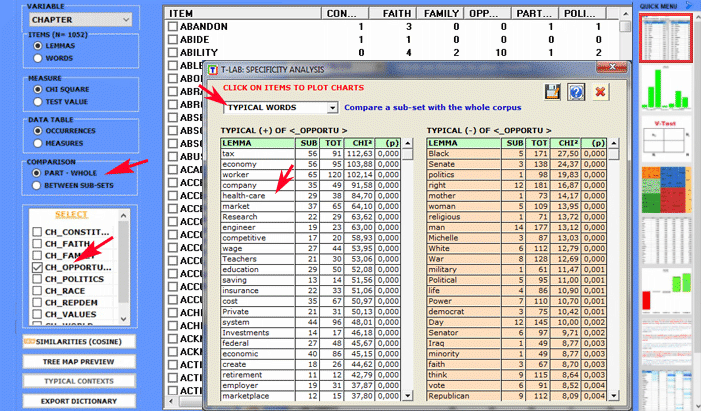
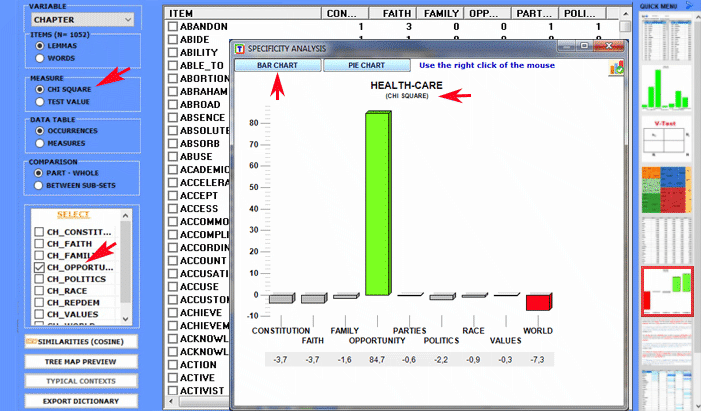
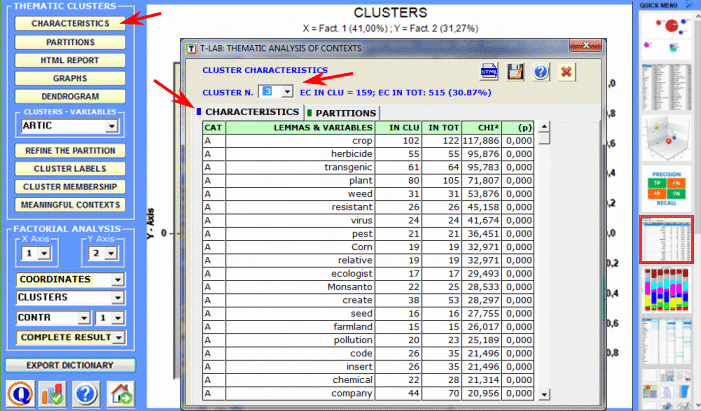
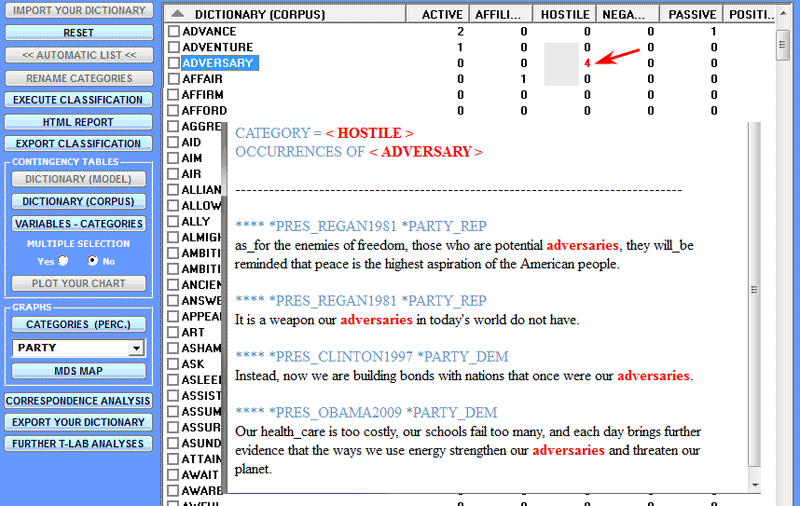
Specificity Analysis enables us to check which words are typical or exclusive of a specific corpus subset, either comparing it with the rest of the corpus or with another subset. Moreover it allows us to extract the typical contexts (i.e. the characteristic elementary contexts) of each analysed subset (e.g. the 'typical' sentences used by any specific political leader).
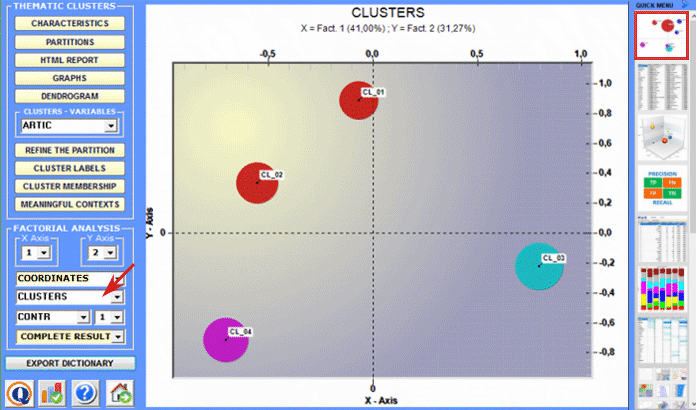
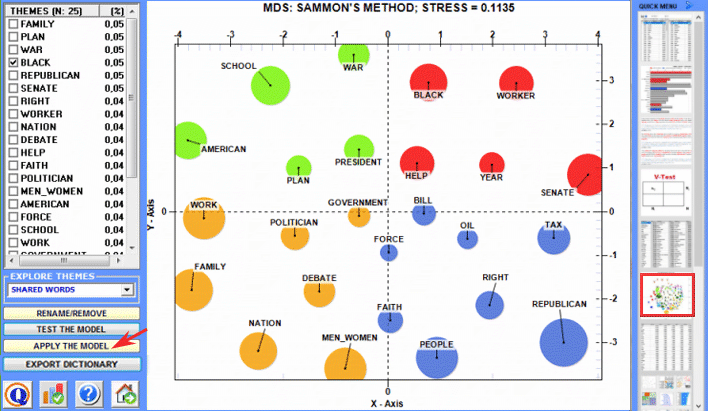
Correspondence Analysis allows us to explore similarities and differences between (and within) groups of context units (e.g. documents belonging to the same category).
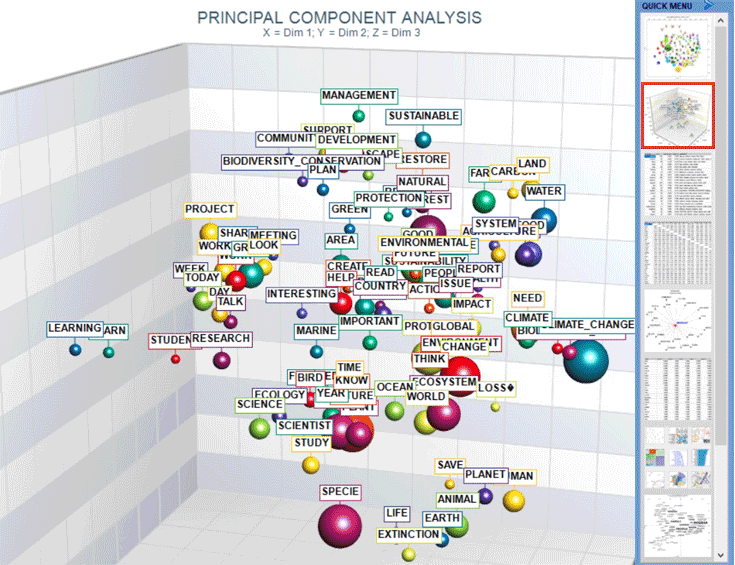
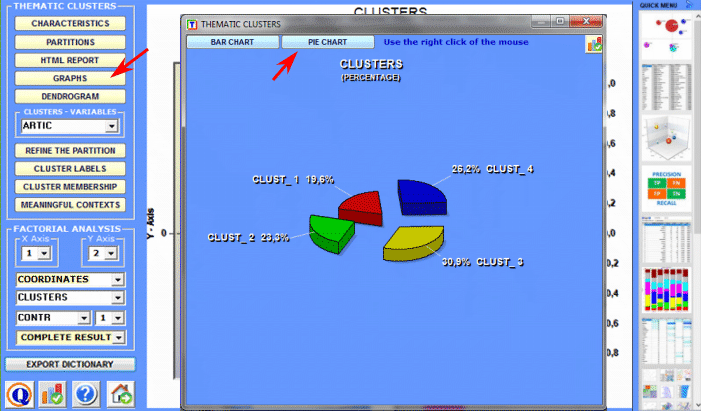
Cluster Analysis , which can be carried out using various techniques, allows us to detect and explore groups of analysis units which have two complementary features: high internal (within cluster) homogeneity and high external (between cluster) heterogeneity.
C : TOOLS FOR THEMATIC ANALYSIS These tools enable us to discover, examine and map
"themes" emerging from texts. 1- a thematic cluster of contexts
units characterized by the same patterns of key-words (see
the Thematic Analysis of Elementary
Contexts, Thematic Document
Classification and Dictionary-Based
Classification tools); For example, depending on the tool we are using, a single
document can be analysed as composed of various 'themes' (see 'A'
below) or as belonging to a set of documents concerning the same
'theme' (see 'B' below). In fact, in the case of 'A' each theme can
correspond to a word or to a sentence, whereas in the case of 'B' a
theme can be a label assigned to a cluster of documents
characterized by the same patterns of key-words.
In detail the ways how T-LAB 'extracts' themes are the following: 1 - both the Thematic Analysis of Elementary Contexts and the Thematic Document Classification tools work in the following way: a - perform
co-occurrence analysis to identify
thematic clusters of context units;
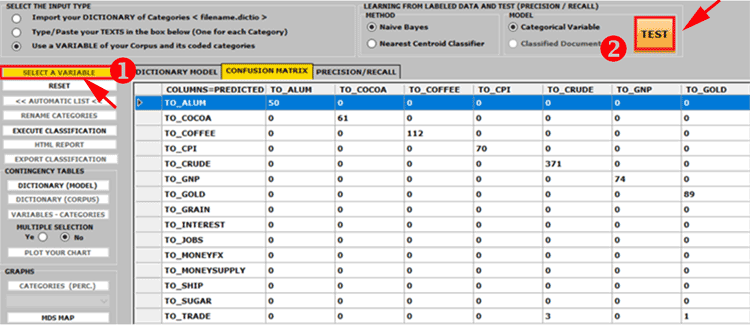
2 - through the Dictionary-Based Classification tool we can easily build/test/apply models (e.g. dictionaries of categories or pre-existing manual categorizations) both for the classical qualitative content analysis and for the sentiment analysis. In fact such a tool allows us to perform an automated top-down classification of lexical units (i.e. words and lemmas) or context units (i.e. sentences, paragraphs and short documents) present in a text collection.
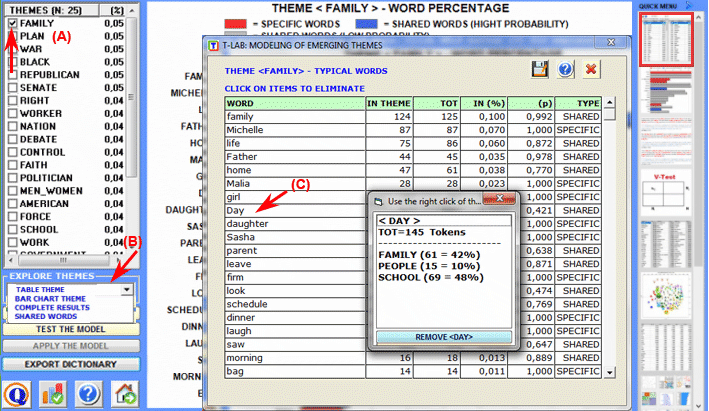
3 - through the Modeling of Emerging Themes tool (see below), the mixture components described through their characteristic vocabulary can be used for building a coding scheme for qualitative analysis and/or for the automatic classification of the context units (i.e. documents or elementary contexts).
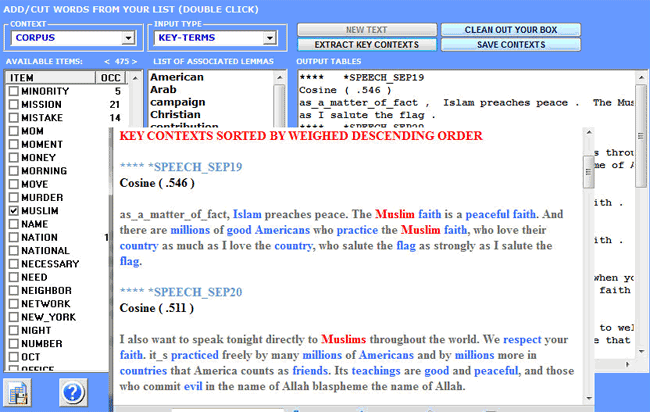
4 - the Key Contexts of Thematic Words tool (see below) can be used for two different purposes: (a) to extract lists of meaningful context units (i.e. elementary contexts) which allow us to deepen the thematic value of specific key words; (b) to extract context units which are the most similar to sample texts chosen by the user.
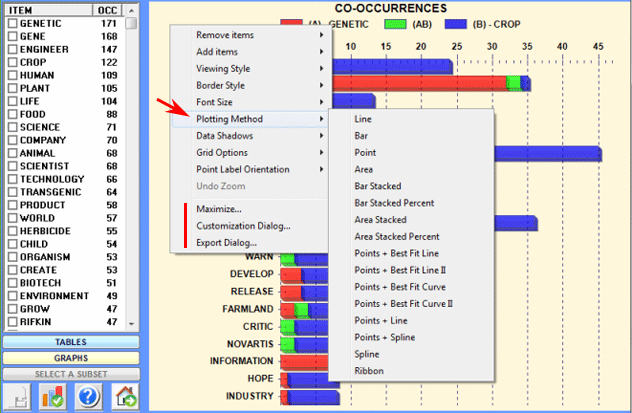
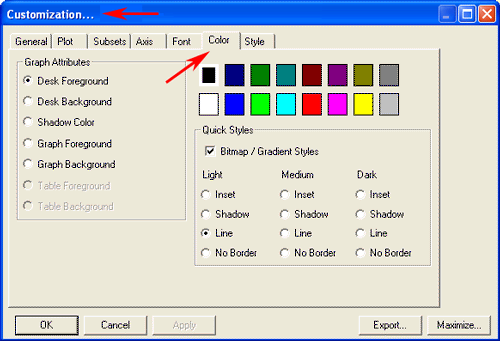
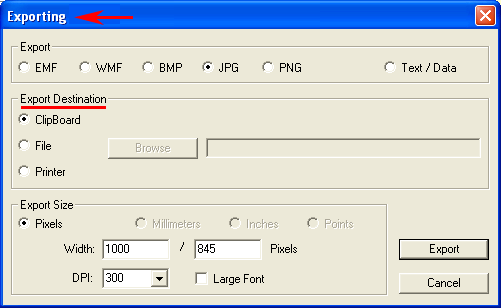
6 - INTERPRETATION OF THE OUTPUTS consists in the consultation of the tables and the graphs produced by T-LAB, in the eventual customization of their format and in making inferences on the meaning of the relationships represented by the same. In the case of tables, according to each case, T-LAB allows the user to export them in files with the following extensions: .DAT, .TXT, .CSV, .XLXS, .HTML. This means that, by using any text editor program and /or any Microsoft Office application, the user can easily import and re-elaborate them. All graphs and charts can be zoomed (left-click and drag), maximized, customized and exported in different formats (right click to show popup menu).
Some general criteria for the interpretation of the T-LAB outputs are illustrated in a paper quoted in the Bibliography (Lancia F.: 2007) and are available from the www.tlab.it website. This document presents the hypothesis that the statistical elaboration outputs (tables and graphs) are particular types of texts, that is they are multi-semiotic objects characterized by the fact that the relationships between the signs and the symbols are ordered by measures that refer to specific codes. In other words, both in the case of texts written in "natural language" and those written in the "statistical language", the possibility of making inferences on the relationships that organize the content forms is guaranteed by the fact that the relationships between the expression forms are not random; in fact, in the first case (natural language) the significant units follow on and are ordered in a linear manner (one after the other in the chain of the discourse), while in the second case (tables and graphs) the organization of the multidimensional semantic spaces comes from statistical measures. Even if the semantic spaces represented in the T-LAB maps are extremely varied, and each of them require specific interpretative procedures, we can theorize that - in general - the logic of the inferential process is the following: A - to detect some
significant relationships between the units "present" on the
expression plan (e.g. between table and/or graph labels);
|







{kind=link}