|
www.tlab.it
Occurrences and
Co-occurrences
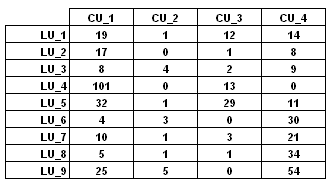
The Occurrences, in fact,
are quantities which result from the computation of how many times
(frequences) a single lexical unit
(LU)occurs within a corpus or within the
context units (CU) in which it is
subdivided.
Their distribution can be represented in contingency tables as
follows:
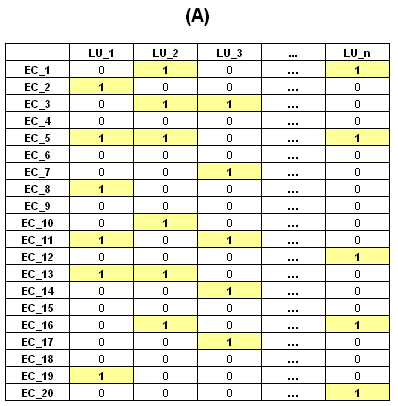
Co-occurrences, then, are
quantities which result from a computation of how many times two or
more lexical units are present together in the same elementary contexts (EC).
Their distribution can be represented in tables such as
the following:
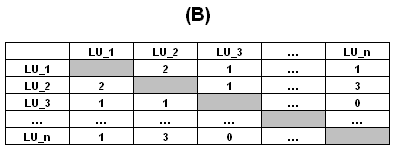
With a simple transformation, the "A" type table
(rectangular) can be transformed into "B" type (squared and
symmetrical) in which for each pair of lexical units the quantity
of their co-occurrences is indicated, that is the total number of
the elementary contexts in which they are present together.
In T-LAB text analysis is mostly carried out by
the study of relationships among occurrences and co-occurrences,
either through specific association
indexes, or through the use of multidimensional statistical
techniques like cluster analysis and
correspondence analysis
|


