|
www.tlab.it
Lemmatization
Lemmatization involves the reduction of corpus words to
their respective headwords (i.e. lemmas). In the linguistic
dictionaries that we may consult, every entry corresponds to a lemma that - generally -
defines a set of words with the same lexical root (or lexeme) and
that belongs to the same grammatical category (verb, adjective,
etc.).
As a rule, lemmatization
entails that verb forms are taken back to the base form, nouns to
the singular form, and so on.
For example, the inflected
forms "speaks" and "speaking", resulting from a combination
of a sole root with two different
suffixes (<-s> and <-ing>), are brought back to the
same lemma "speak". There are, however, some cases in which the
lemmatization doesn't observe the rule of the common root;
particularly in the case of many irregular verbs.
During the corpus importation
phase, T-LAB carries
out a specific kind of automatic lemmatization, that follows the
logic of the following "tree".
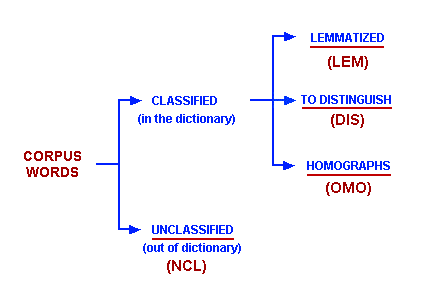
Obviously, the reference dictionary is the one
implemented in T-LAB.
The abbreviations of the four-categories are used in many
tables, always in the "INF" column (or field).
N.B.:
- the "DIS" category ("to distinguish") means that T-LAB
does not apply the standard lemmatization, in order to avoid
annulling the significant meanings among the different forms;
- sometimes, in order to differentiate homographs, T-LAB
adds the underscore ('_') character to their lemma.
|


