|
www.tlab.it
Contesto Elementare
Nella fase di importazione, T-LAB effettua una segmentazione del corpus
in contesti elementari: ciò per facilitarne l'esplorazione da parte
dell'utilizzatore e, soprattutto, per effettuare analisi che
richiedono il calcolo delle co-occorrenze.
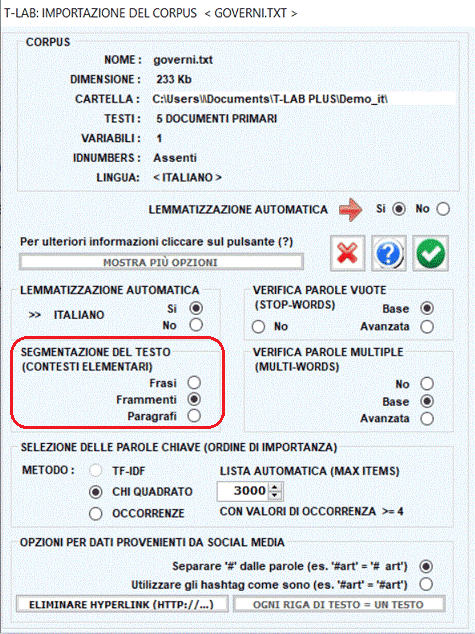
Ne risulta che, a seconda delle scelte
dell'utilizzatore, i contesti elementari possono essere di quattro
tipi:
1 - Frasi
Contesti elementari marcati dalla punteggiatura forte (.? ! ), con
lunghezza minima di 50 caratteri (Max. 1000 caratteri).
2 - Frammenti
Contesti elementari di lunghezza comparabile costituiti da uno o
più enunciati.
In questo caso, l'algoritmo di segmentazione
rispetta le seguenti regole:
- considerare come contesto elementare ogni sequenza di
parole interrotta dal "punto e capo" (ritorno di carrello) e le cui
dimensioni siano inferiori 400 caratteri;
- nel caso in cui, entro la lunghezza massima, non sia
presente alcun punto e a capo, cercare, nell'ordine, altri segni di
punteggiatura (? ! ; : ,). Se non vengono trovati, segmentare in
base a un criterio statistico, ma senza troncare le unità
lessicali.
3 - Paragrafi
Contesti elementari marcati dalla punteggiatura forte (.? ! ) e dal
ritorno di carrello, con lunghezza massima di 2000
caratteri.
4 - Testi Brevi
Questa opzione è abilitata solo quando il corpus è costituito da
testi con dimensione massima di 2000 caratteri (es. risposte a
domande aperte).
N.B.:
- il file corpus_segments.dat
contiene il risultato della segmentazione del corpus;
- la funzione concordanze consente la verifica dei contesti
elementari in cui ogni parola (forma
grafica o lemma) è
presente.
|


