|
www.tlab.it
Vocabolario del
Corpus
Questo strumento T-LAB consente
di verificare in Vocabolario del corpus e dei suoi sottoinsiemi
(vedi sotto opzione '1').
Inoltre fornisce alcune misure della ricchezza lessicale.
La tabella Vocabolario
è una lista che include le "parole" (cioè i word types), le loro
occorrenze (cioè i word tokens), i corrispondenti lemmi e alcune categorie utilizzate da
T-LAB (vedi
Glossario/Lemmatizzazione).
L'utilizzatore può agevolmente
selezionare (vedi sotto opzione '2' ) le unità lessicali che
appartengono a ciascuna categoria, consultare la relativa tabella
ed esportarla in formato .xls (vedi sotto opzione '3').
Inoltre, usando il tasto destro del
mouse, è possibile verificare le concordanze (Key-Word-in-Context) di ogni parola
(vedi sotto opzione '4').
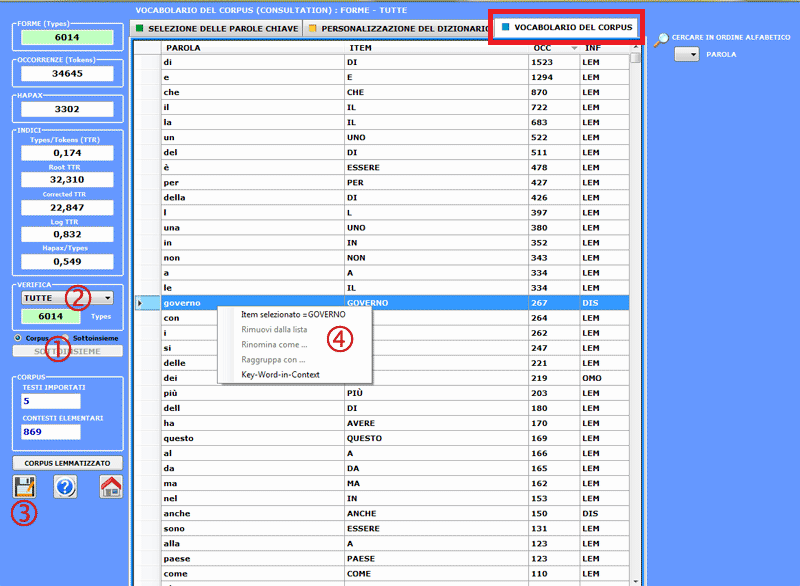
Le misure della ricchezza lessicale
sono cinque:
Type/Token ratio (TTR);
Root TTR (Guiraud, 1960), ottenuta dividendo la quantità dei type
per la radice quadrata dei token;
Corrected TTR (Carroll, 1964), ottenuta dividendo la quantità dei
type per la radice quadrata di due volte la quantità dei token;
Log TTR (Herdan, 1960), ottenuta dividendo il logaritmo dei type
per il logaritmo dei token;
Hapax/Types ratio.
N.B.:
- Hapax (i.e. Hapax Legomena) sono parole (type) che occorrono una
sola volta nel corpus;
- quando vengono analizzati sottoinsiemi del corpus, tutte le
misure della ricchezza lessicale non includono le stop words.
|


