|
TF-IDF
Questa misura, proposta da Salton (1989)
nell'ambito dell'Information Retrieval, consente di valutare
l'importanza di un termine (unità lessicale) all'interno di un
documento (unità di contesto).
La sua formula è la seguente:
w i,j =
tf i,j x idf i (Term Frequency x Inverse
Document Frequency)
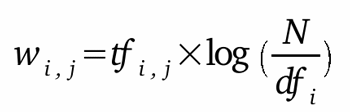
Dove:
tf i,j = numero
delle occorrenze di i (un termine) all'interno di
j (un documento)
df i = numero dei documenti che
contengono i
N = totale dei documenti che
costituiscono il corpus in analisi
Il valore tf
i,j (Term
Frequency) può essere
normalizzato nel modo seguente:
tf i,j
= tf i,j / Max
(f i,j )
dove Max (f i,j ) è la
frequenza massima di i (un qualunque termine)
all'interno di j (documento).
|


