|
www.tlab.it
Importare un singolo
file...
Nel caso di un unico testo (o di un corpus trattato
come unico testo) T-LAB non
richiede ulteriori accorgimenti: basta selezionare l'opzione
'Importare un singolo file…' (vedi sotto).
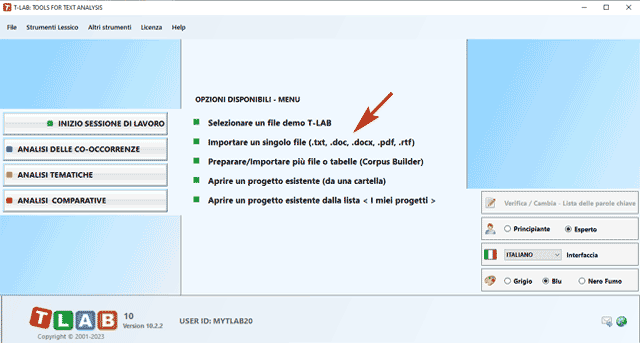
Quindi si richiedono quattro passaggi (vedi
immagine seguente) : (1) selezionare un qualsiasi file; (2)
scegliere il nome del progetto; (3) selezionare la lingua del
testo; (4) cliccar su 'Importa' .
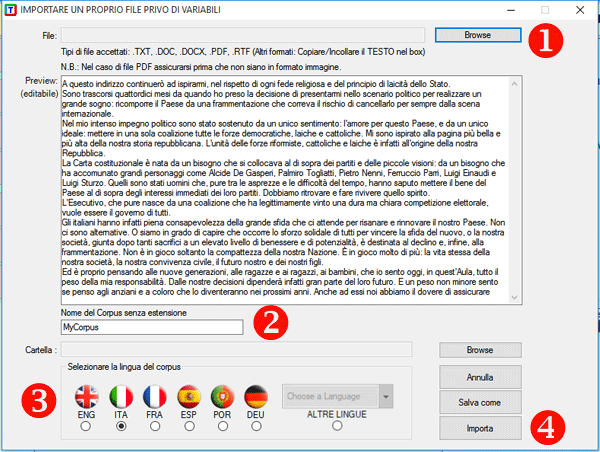
Successivamente compare una finestra di riepilogo
(vedi immagini seguenti) in cui possono essere effettuate alcune
scelte.
N.B.:
- Poiché i trattamenti preliminari determinano il tipo e la
quantità delle unità di analisi (cioè quali e quante unità di
contesto e quali e quante unità lessicali), scelte diverse in
questa fase comportano risultati diversi delle successive analisi
(vedi sotto opzioni avanzate). Per questa ragione, tutti gli output
T-LAB
mostrati nel manuale e nell'help hanno solo valore indicativo;
- Tutte le fasi di pre-processing vengono eseguite durante
l'importazione di qualsiasi tipo di corpus.
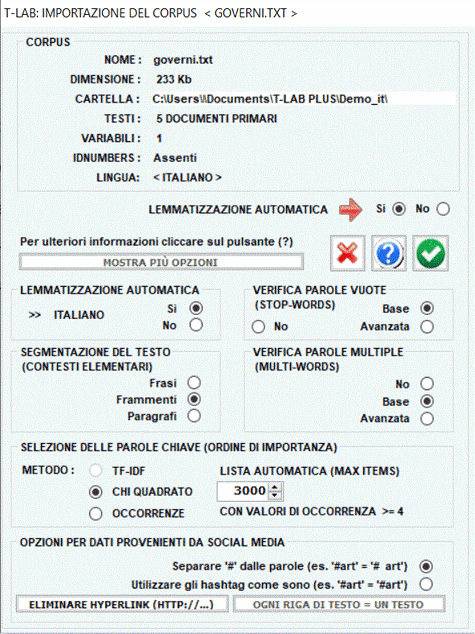
1 - LEMMATIZZAZIONE AUTOMATICA O STEMMING
Di seguito la lista complete delle trenta (30) lingue per le quali
T-LAB
supporta la lemmatizzazione automatica o lo stemming.
LEMMATIZZAZIONE: catalano, croato,
francese, inglese, italiano, latino, polacco, portoghese, rumeno,
russo, serbo, slovacco, spagnolo, svedese, tedesco, ucraino;
STEMMING: arabo, bengali, bulgaro,
ceco, danese, finlandese, greco, hindi, indonesiano, marathi,
norvegese, olandese, persiano, turco, ungherese.
In ogni caso, senza lemmatizzazione automatica e/o
usando dizionari personalizzati, possono essere analizzati testi in
tutte le lingue le cui parole siano separate da spazi e/o da
punteggiatura.
Il risultato del processo di lemmatizzazione può essere verificato
tramite la funzione Vocabolario e può
essere modificato tramite la funzione Personalizzazione del Dizionario.
Se l'utilizzatore intende analizzare testi di lingue diverse, si
consiglia di selezionare l'opzione "other".
2 - SEGMENTAZIONE DEI TESTI IN CONTESTI ELEMENTARI
A seconda della scelta dell'utilizzatore, i contesti elementari per il calcolo delle
co-occorrenze possono essere di quattro
tipi: frasi, frammenti di lunghezza comparabile, paragrafi e testi
brevi (es. risposte a domande aperte).
Il risultato del processo di segmentazione può essere verificato
tramite il file corpus_segments.dat.
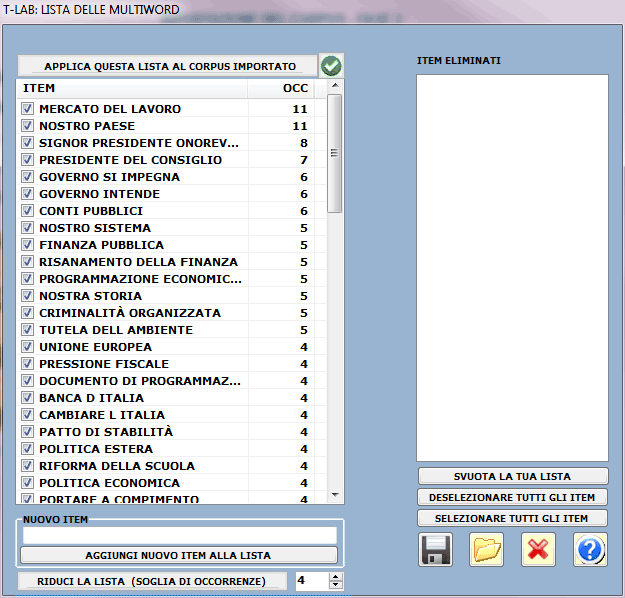
3 - VERIFICA DELLE PAROLE MULTIPLE (MULTI-WORDS)
L'opzione "Base" abilita l'uso automatico
della lista multi-words di
T-LAB.
Diversamente, l'opzione "Avanzata", abilitata solo
in caso di lemmatizzazione automatica, consente di verificare e
modificare la lista delle multi-words presenti nel corpus e non
incluse nel dizionario T-LAB
(vedi immagine seguente). Inoltre è possibile importare e usare
altre liste predisposte
dall'utilizzatore (file Multiwords.txt).
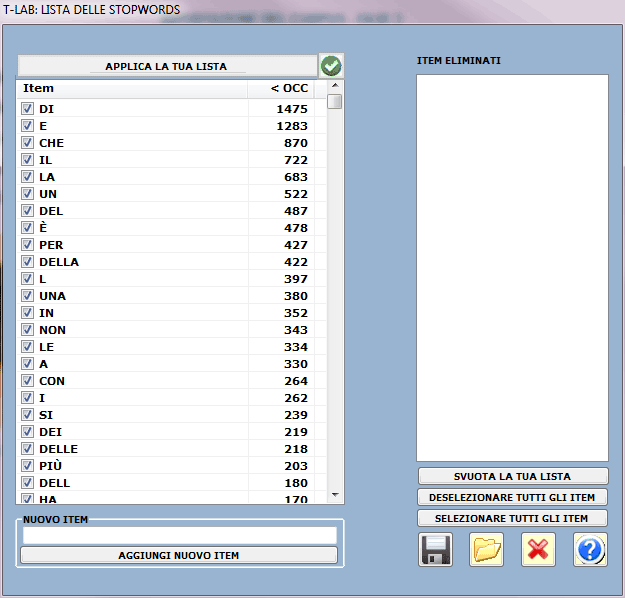
4 - VERIFICA DELLE PAROLE VUOTE (STOP-WORDS)
L'opzione "Base" abilita l'uso automatico della lista parole vuote di T-LAB.
Diversamente, l'opzione "Avanzata" consente di
verificare e modificare la lista delle parole vuote presenti nel
corpus.
Inoltre è possibile importare e usare altre liste predisposte dall'utilizzatore (file
Stopwords.txt).
5 - SELEZIONE DELLE PAROLE CHIAVE
Le opzioni disponibili consentono di scegliere il metodo di
selezione (TF-IDF o Chi-quadro) e il numero massimo di unità lessicali
da includere nella lista usata da T-LAB per
analizzare i testi con impostazioni
automatiche.
N.B.: Al termine della fase di
importazione, mediante le impostazioni
personalizzate, l'utilizzatore può rivedere la selezione delle
parole e costruire varie liste da applicare.
|


