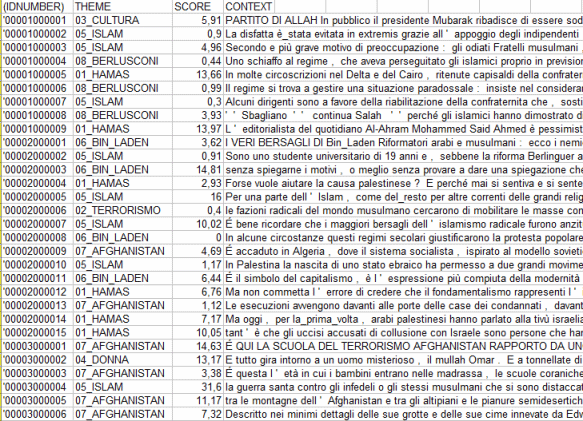
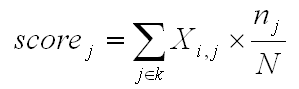|
|
T-LAB 10.2 - HELP ON-LINE |
|
|
www.tlab.it
Analisi Tematica dei Contesti Elementari
Questo strumento T-LAB consente di costruire ed esplorare una rappresentazione dei contenuti del corpus attraverso pochi e significativi cluster tematici (minimo 3, massimo 50), ciascuno dei quali: a) risulta costituito da un insieme contesti elementari (frasi, paragrafi o testi
brevi quali risposte a domande aperte) caratterizzati dagli stessi
pattern di parole chiave; Per molti versi, si può affermare che il risultato dell'analisi propone una mappatura delle isotopie (iso = uguale; topoi = luoghi) intese come temi "generali" o "specifici" (Rastier, 2002: 204) caratterizzati dalla co-occorrenza di tratti semantici. In effetti ogni cluster, caratterizzato da insiemi di unità lessicali che condividono gli stessi contesti di riferimento, consente di ricostruire "un filo" del discorso all'interno della trama complessiva costituita dal corpus o da un suo sottoinsieme. Il processo di analisi può essere effettuato tramite un metodo di clustering 'non supervisionato' (nel caso specifico, un algoritmo bisecting K-Means) o tramite una classificazione 'supervisionata' (vale a dire approccio top-down). Quando si sceglie il secondo (cioè classificazione supervisionata), viene richiesto di importare un dizionario delle categorie, sia esso creato tramite una precedente analisi T-LAB che costruito dall'utilizzatore.
In particolare: - il parametro (A) permette di fissare il numero massimo
di partizioni da includere negli output T-LAB; N.B.: Nel caso di clustering non supervisionato (opzione di default), la procedura di analisi è costituito dai seguenti step: a - costruzione di una tabella dati unità di contesto x
unità lessicali (max 300.000 righe x 5.000 colonne), con valori del
tipo presenza/assenza; N.B.: A partire da T-LAB Plus 2016, la clusterizzazione
delle unità di contesto (vedi sopra step 'c') può essere ottenuta
sia usando l'algoritmo bisecting K-means algorithm (1) che usando
una versione 'not centered' dell'algoritmo PDDP(Principal Direction
Divisive Partitioning) proposto da D. Booley (1998) per selezionare
i centroidi delle varie bisezioni K-means. Quindi, questa procedura realizza un tipo di analisi delle co-occorrenze (step a-b-c) e, a seguire, un tipo di analisi comparativa (e-f-g). In particolare, l'analisi comparativa usa come colonne delle tabelle di contingenza le modalità della "nuova variabile" derivata dall'analisi delle co-occorrenze (modalità della nuova variabile = cluster tematici). N.B.: Quando l'utilizzatore decidere di ripetere/applicare i risultati di una precedente analisi tematica (sia Analisi Tematica dei Contesti Elementari che Modellizzazione dei Temi Emergenti), T-LAB realizza soltanto un'analisi comparativa dei cluster già ottenuti (passi e-f-g). Nel caso di classificazione
supervisionata, le fasi dell'analisi comparativa sono le
stesse (vedi sopra e-f-g), mentre l'analisi delle co-occorrenze
viene eseguita come segue: Al termine dell'analisi l'utilizzatore può agevolmente effettuare le seguenti operazioni:
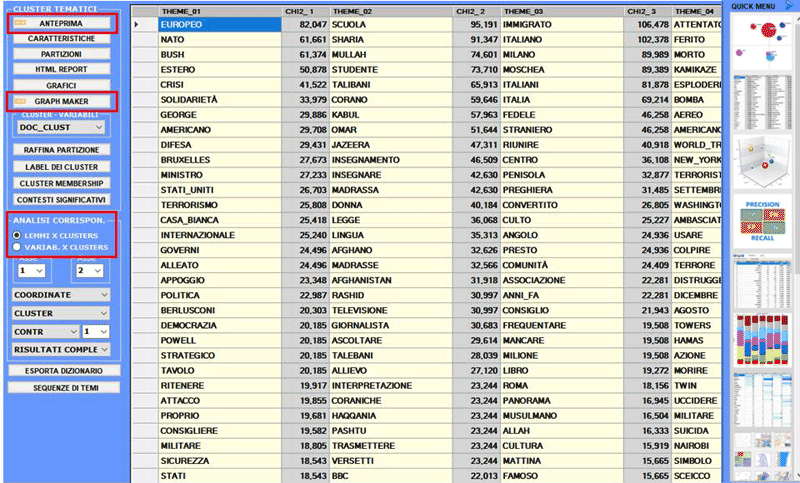
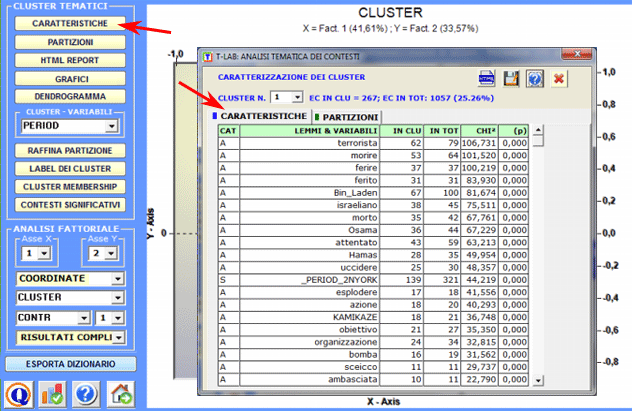
Nel dettaglio: 1 - Esplorare le
caratterisitiche dei cluster
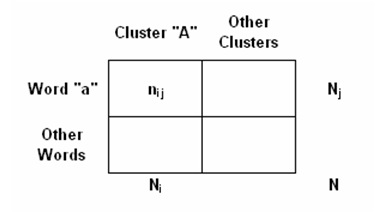
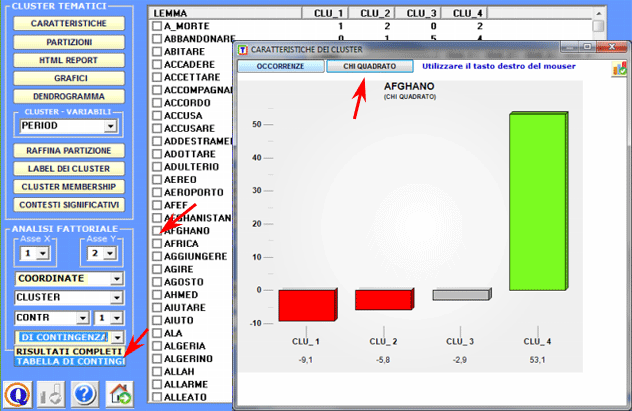
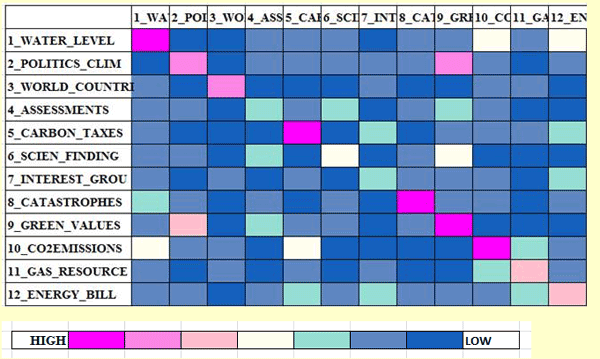
Nel caso del test del chi quadro la struttura della tabella analizzata è la seguente:
Un report HTML (vedi sotto) consente una dettagliata verifica delle caratteristiche dei cluster. In questo, oltre alla lista delle parole tipiche, vengono mostrati - ordinati in modo decrescente in base al rispettivo peso (score) - i contesti elementari che più caratterizzano il cluster in esame.
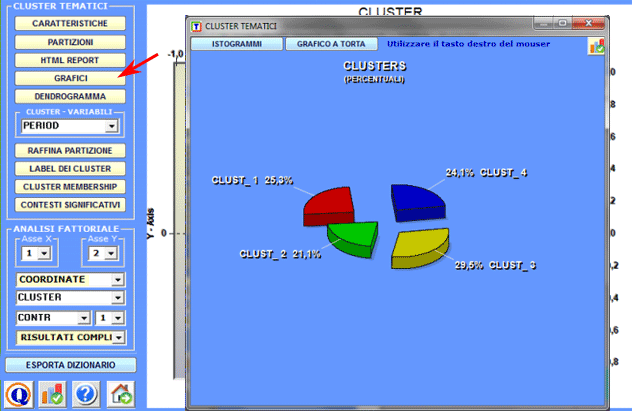
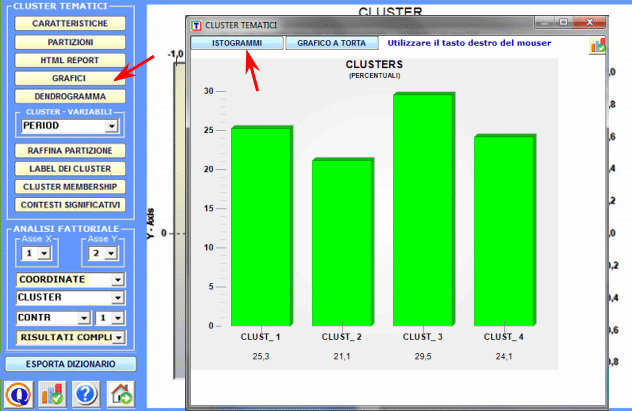
Grafici a torta e istogrammi (vedi sotto) consentono di verificare la percentuale delle unità di contesto appartenenti ad ogni cluster.
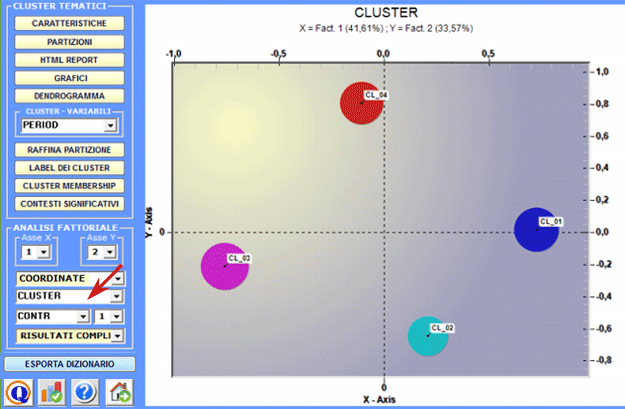
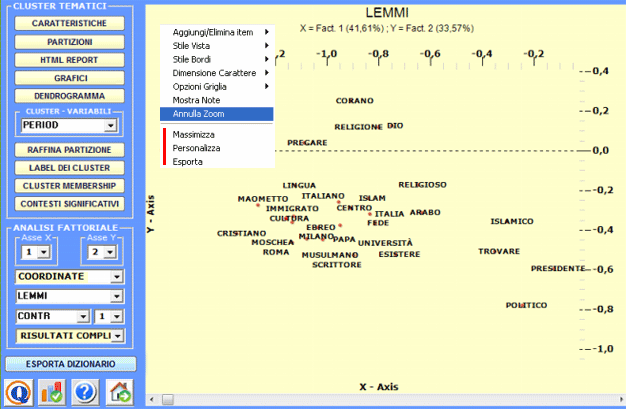
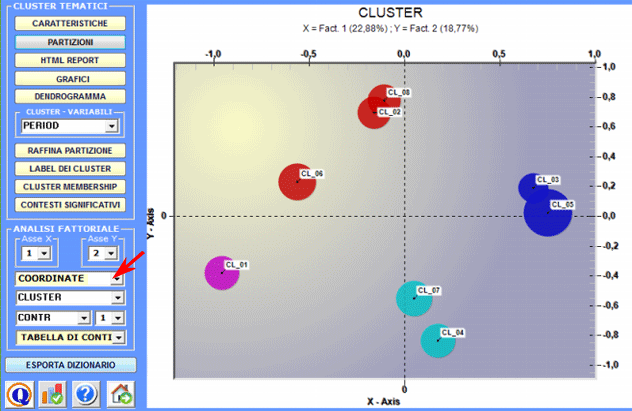
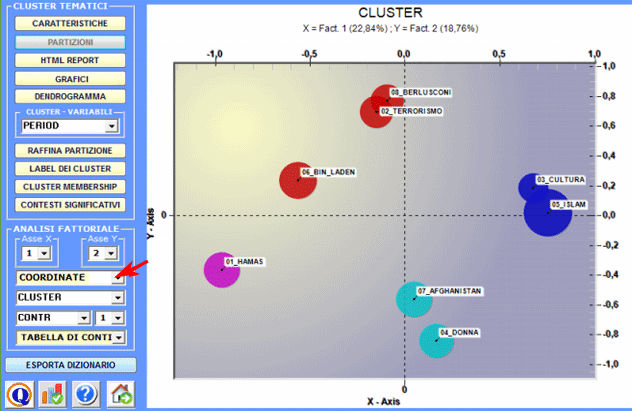
2 - Esplorare le relazioni tra cluster Alcuni grafici, ottenuti tramite Analisi delle
Corrispondenze consentono di esplorare le relazioni tra
i cluster all'interno di spazi bidimensionali.
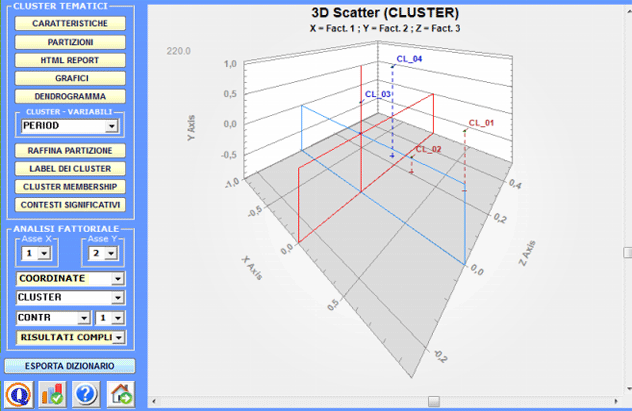
Tutti i grafici possono essere personalizzati tramite l'uso di apposite finestre di dialogo (uso del tasto destro del mouse). Inoltre quando i cluster tematici sono più di tre, le loro relazioni possono essere esplorate tramite grafici 3D (vedi sotto).
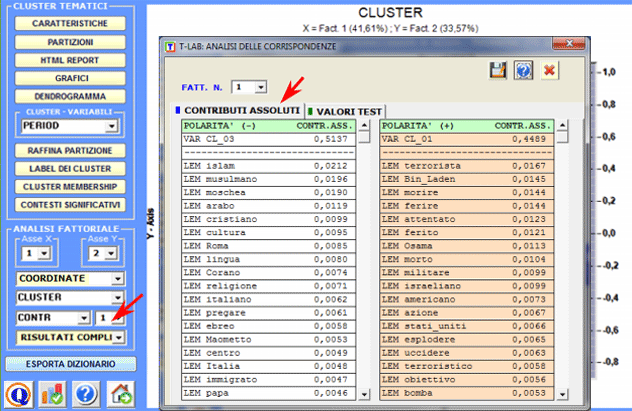
Come nella funzione Analisi delle Corrispondenze, selezionando gli appositi pulsanti (vedi sotto) compaiono delle tabelle che riportano le caratteristiche delle polarità fattoriali in esame (X-Y).
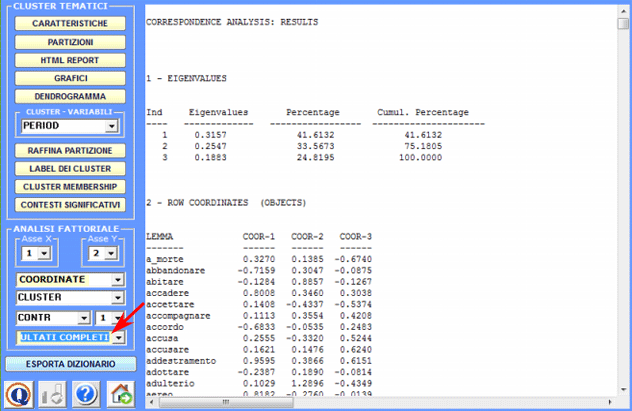
Una specifica opzione (vedi sotto) consente di visualizzare ed esportare i Risultati Completi dell'analisi delle corrispondenze unità lessicali x cluster.
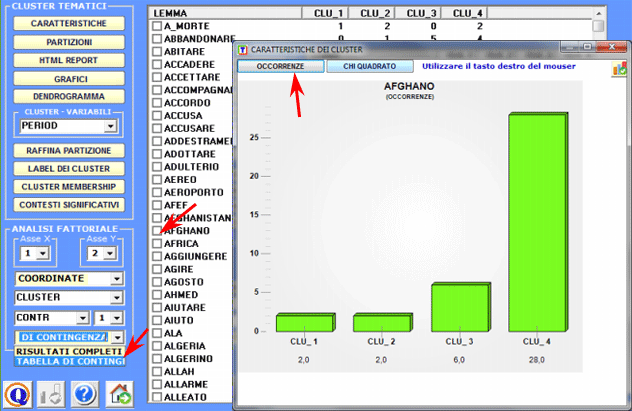
Una ulteriore
opzione (vedi sotto) consente di visualizzare/esportare la
Tabella di Contingenza e di creare
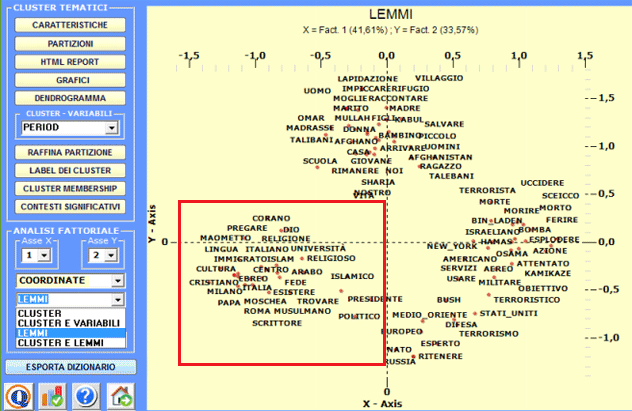
grafici che mostrano sia le distribuzioni delle singole parole
all'interno dei cluster che i rispettivi valori del chi
quadrato. N.B.: In questa tabella sono incluse sia le parole 'attive' ('A') che quelle 'supplementari' ('S').
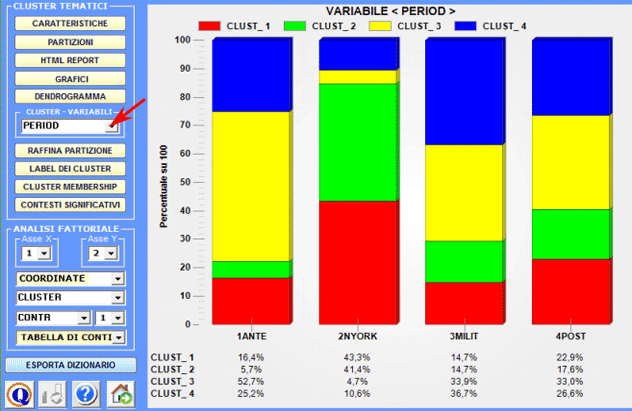
3 - Esplorare le relazioni tra cluster e variabili Alcuni istogrammi consentono di verificare le relazioni tra cluster e modalità delle variabili.
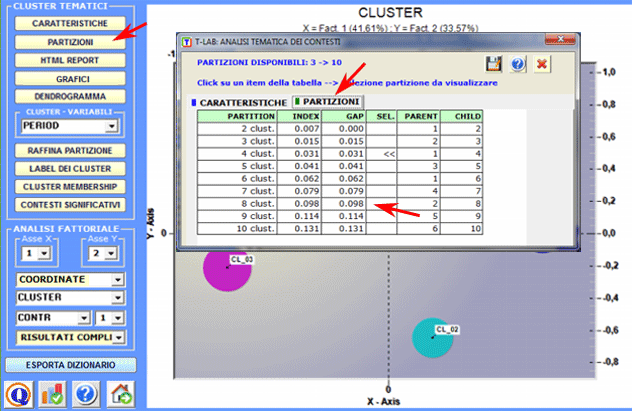
Ulteriori relazioni tra cluster e variabili possono essere esplorate con le opzioni disponibili nella sezione Analisi Fattoriale (vedi sopra) 4 - Esplorare le diverse partizioni Poiché l'algoritmo usato da T-LAB
(bisecting K-Means) produce una clusterizzazione gerarchica,
l'utilizzatore può agevolmente esplorare diverse soluzioni
dell'analisi: partizioni da 3 a 50 clusters.
L'opzione partizioni (vedi sopra) consente di esplorare agevolmente le caratteristiche delle varie soluzioni disponibili.
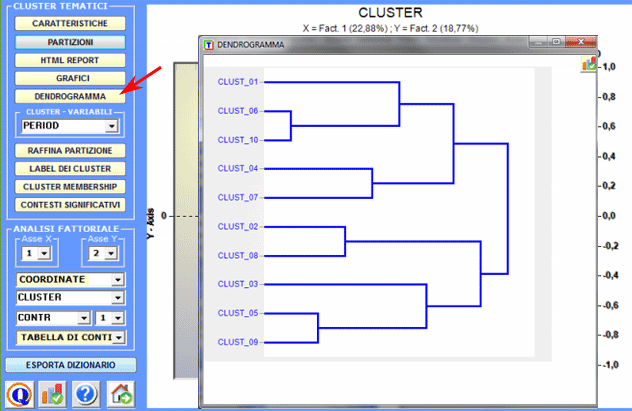
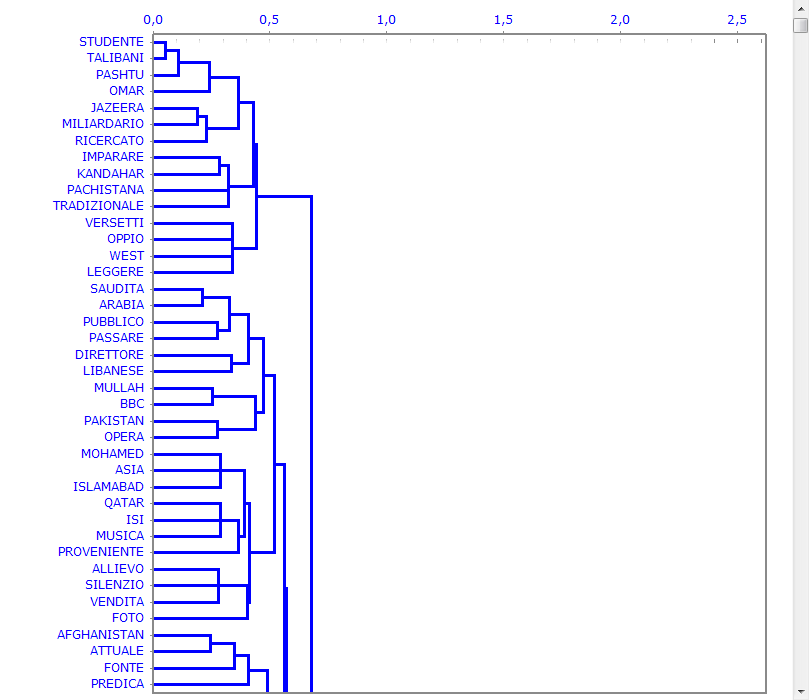
Inoltre l'opzione dendrogramma (vedi sotto) consente due possibilità: A) verificare l'albero delle varie bi-sezioni dei cluster;
B) verificare l'albero delle parole caratteristiche a ciascun cluster.
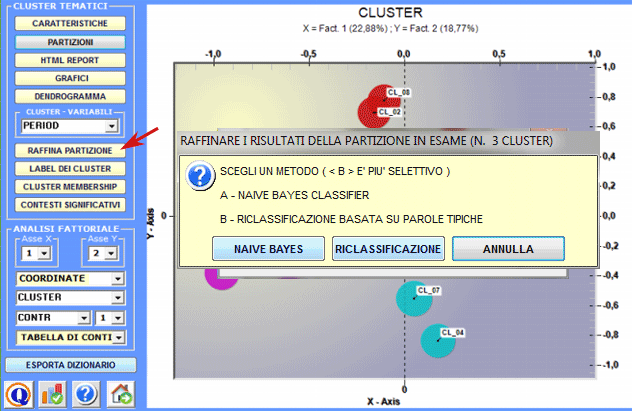
5 - Raffinare i risultati della partizione prescelta Dopo aver esplorato diverse soluzioni, l'utilizzatore può raffinare i risultati della partizione prescelta e, se necessario, ripetere alcuni dei passi sopra descritti (1,2,3). A questo scopo sono disponibili due metodi (vedi immagine seguente).
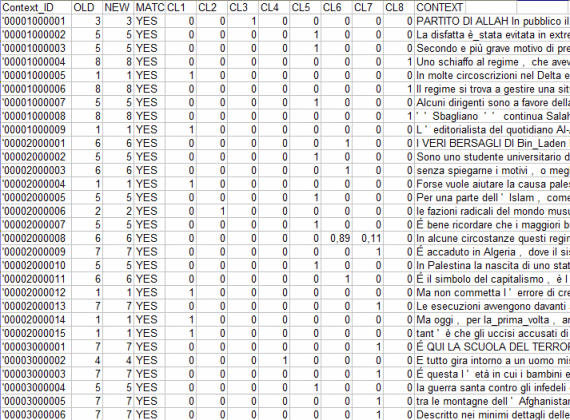
Diversamente, nel caso del metodo di 'B' (cioè Riclassificazione basata su base Parole Tipiche) T-LAB considera le caratteristiche del cluster, cioè le parole con un significativo valore de Chi-Quadro, come item di un dizionario delle categorie ed esegue le tre fasi della 'classificazione supervisionata' descritte all'inizio di questa sezione. Quindi, quando l'utente è interessato a ri-applicare dizionari e a comparare i relativi risultati, si consiglia vivamente di usare questo metodo. Tutti i risultati di questo calcolo sono in una tabella esportata da T-LAB (vedi sotto), che contiene i valori delle probabilità a posteriori espressi in termini percentuali.
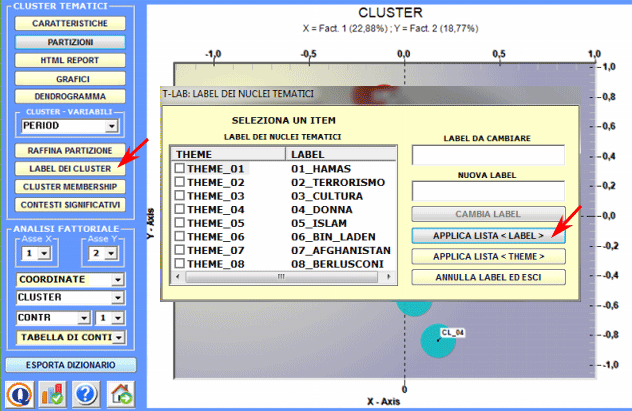
6 - Assegnare label ai cluster Un'apposita funzione T-LAB
consente di attribuire label ai cluster.
Le label attribuite ai vari cluster possono essere visualizzate nei vari grafici disponibili (vedi sotto).
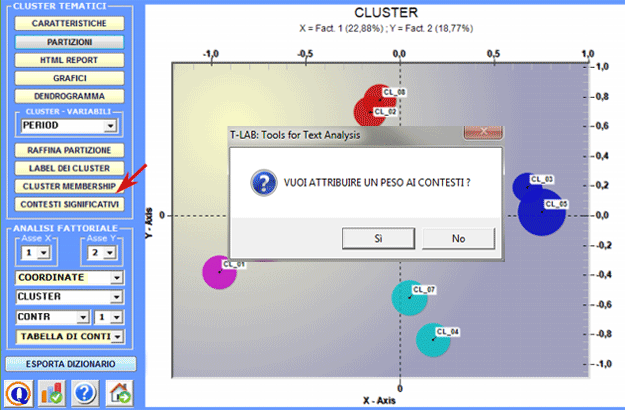
7 - Verificare quali contesti
elementari appartengono a ciascun cluster
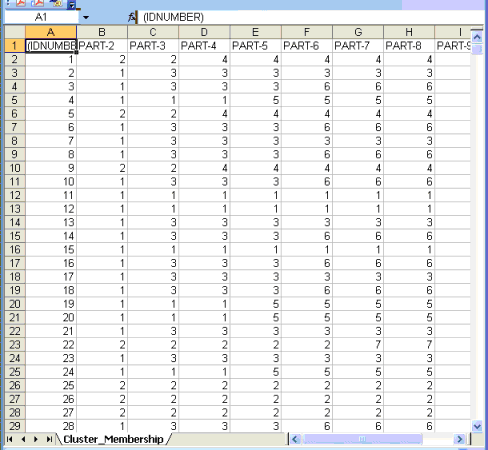
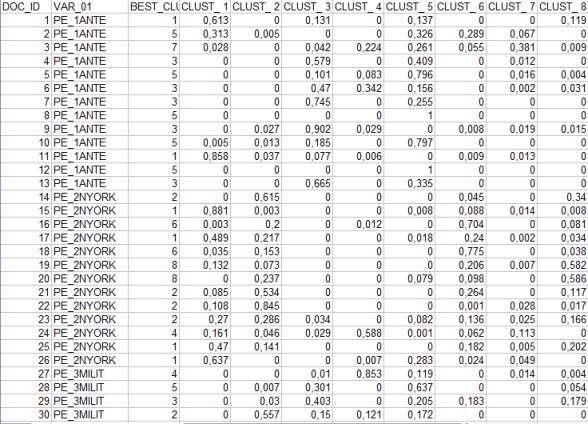
Infatti il pulsante Cluster Membership consente di esportare tre tipi di tabelle (vedi sotto) in formato MS Excel: a - "Cluster_Partitions.xls", con tutte le corrispondenze unità di contesto x cluster all'interno delle varie partizioni;
In particolare, il valore di rilevanza (score) assegnato ad ogni j-contesto elementare appartenente al k-cluster è calcolato nel modo seguente:
Dove: Scorej = valore di rilevanza attribuito al contesto elementare (j); SXij = somma dei valori del chi-quadrato corrispondenti alle parole chiave (i) trovate nel contesto elementare in questione (j) e che sono risultate tipiche del cluster (k); nj = totale delle parole chiave (parole distinte), tipiche del cluster (k), trovate nel contesto elementare (j); N = totale delle parole chiave (parole distinte)
tipiche del cluster (k).
c - " Ec_Document_Classification.xls" (output fornito
solo nel caso in cui il corpus è costituito da almeno 2 documenti
primari e questi non sono testi corti trattati come contesti
elementari) che elenca le "appartenenze miste" di ogni documento
(vedi sotto).
In questo caso i valori derivano dalla formula già illustrata (vedi punto "b"), sommando gli score dei contesti elementari appartenenti a ogni documento ed applicando un calcolo di percentuali. 10 - Archiviare la partizione selezionata per esplorarla con altri strumenti T-LAB All'uscita dalla funzione Analisi Tematica dei Contesti Elementari, alcuni messaggi ricordano che è possibile esplorare i cluster ottenuti con altri strumenti T-LAB.
Scegliendo l'opzione "Salva", la variabile < CONT_CLUST > (cluster di contesti elementari) resta disponibile solo in alcuni tipi di analisi (es. Sequenze di Temi, Associazioni di Parole, Confronti tra Coppie e Co-Word Analysis) e fino a quando l'utilizzatore modifica la lista delle parole chiave. 11 - Esportare un dizionario delle categorie Quando viene selezionata questa opzione, T-LAB crea due files: - un file dizionario con estensione .dictio pronto per essere importato tramite uno
degli strumenti per l'analisi tematica. In tale dizionario ciascun
cluster corrisponde a una categoria descritta tramite le sue parole
caratteristiche, cioè da tutte le parole con un significativo
valore del chi-quadro al suo interno; 12 - Verificare la qualità della partizione scelta e la coerenza semantica dei vari temi
Quando viene cliccato il pulsante Indici di Qualità (vedi sopra),
T-LAB
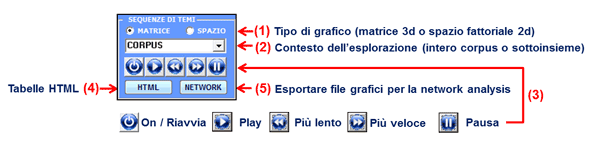
crea un file HTML in cui sono riportate varie misure. 13 - Esplorare Sequenze di Temi A differenza dello strumento Sequenze di Temi incluso in un sottomenu T-LAB per l'analisi delle co-occorrenze, questa opzione è stata specificamente progettata per integrare l'analisi tematica dei contesti elementari. Più specificamente: il suo uso ha senso solo quando l'intero corpus può essere considerato come un discorso e/o quando le sue varie sezioni (ad esempio: capitoli di un libro, parti di una intervista, interventi di vari partecipanti a una conversazione o una discussione, etc.) si susseguono con un preciso ordine temporale. In questo caso le relazioni analizzate sono quelle tra contesti elementari (fino a un massimo di 100.000) lungo la catena lineare del corpus, e ciascuno di essi - vuoi come 'predecessore' o come 'successore' - è trattato come una unità di analisi appartenente ad un cluster tematico (o come non classificato). Tutti gli output forniti permettono all'utente di esplorare le relazioni sequenziali tra 'temi', sia in modo 'statico' che 'dinamico'. In particolare, tramite alcuni grafici animati che consentono di apprezzare la dinamica temporale delle sequenze, l'utente può verificare quando le persone sono impegnate su temi specifici (vedi, ad es., i punti sulla diagonale delle matrici nelle immagini seguenti) e quando passano da un tema dominante a un altro. Passo dopo passo, di seguito viene fornita una breve descrizione delle varie opzioni disponibili. (N.B.: Tutti gli output dell'esempio sono stati ottenuti tramite un'analisi tematica del libro The Politics of Climate Change di Antony Giddens pubblicata su sito T-LAB). Quando è abilitato il pulsante Sequenze di Temi, cliccando su di esso diventa visibile ed attivo il seguente 'player'.
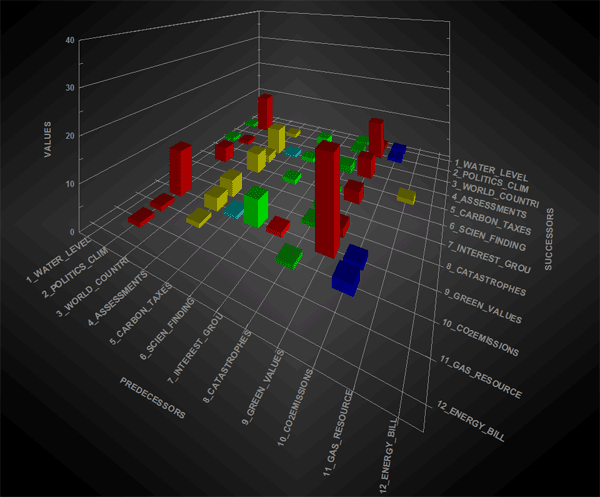
L'opzione '1' (vedi sopra) si riferisce al tipo di grafico scelto per la visualizzazione delle sequenze, sia all'interno dell'intero corpus che all'interno una parte di esso (vedi sopra opzione '2'). L'opzione 'matrice' rende disponibile un grafico 3D che riassume le relazioni tra predecessori e successori tramite barre colorate posizionate ai rispettivi incroci. In questo caso, quando sono visualizzati grafici 3D animati, l'incremento in altezza delle varie barre indica l'aumento delle occorrenze delle rispettive sequenze (vedi relazioni binarie tra 'predecessori' e 'successori' nel grafico seguente).
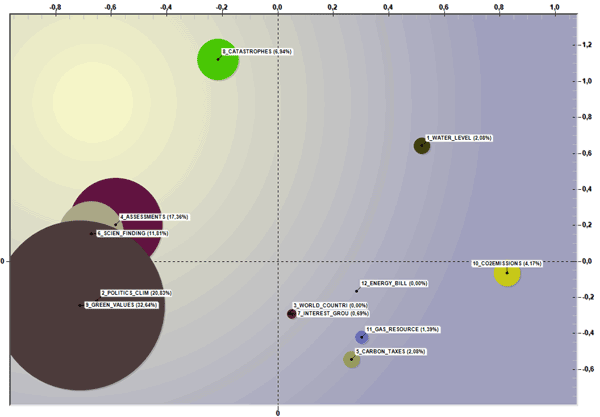
L'opzione 'spazio' rende disponibile un grafico 2d in cui le dimensioni (cioè percentuali) e le relazioni tra gruppi tematici sono rappresentate su un piano organizzato da due assi fattoriali selezionati dall'utilizzatore. In questo caso, quando sono visualizzati grafici animati, le dimensioni delle 'bolle' - che vengono continuamente riadattate a un totale pari al 100 % - indicano come la percentuali degli elementi appartenenti a ogni cluster tematico variano nel tempo e, contemporaneamente, il movimento delle frecce indica la direzione in cui i temi si susseguono.
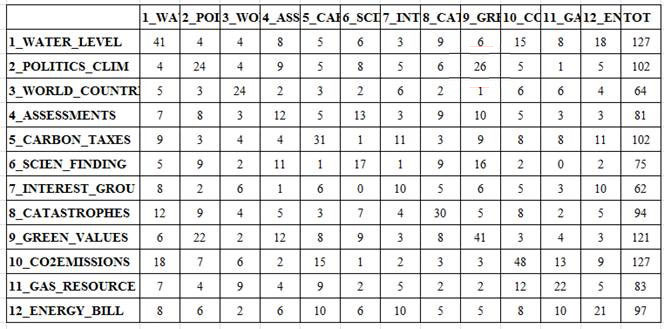
In entrambi i casi appena descritti, dopo l'arresto del video (vedi pulsante 'pausa'), è possibile visualizzare due ulteriori output: A - tabelle html che riassumono i rapporti tra predecessori e successori (vedi sotto);
B - file grafici che possono essere importati da software per l'analisi di rete.
N.B.: Il grafico precedente, che si riferisce al terzo
capitolo del libro di Giddens, è stato creato per mezzo del
software Gephi (vedi https://gephi.org/).
|