|
www.tlab.it
Analisi delle Sequenze e
Network Analysis
Questo strumento T-LAB tiene
conto delle posizioni delle varie unità lessicali
all'interno delle frasi e ci permette di rappresentare ed esplorare
qualsiasi testo come una rete di relazioni.
Le varie opzioni disponibili possono essere
utilizzate per scopi quali Co-Word Analysis, Analisi Tematiche e
Disambiguazioni.
Infatti, dopo aver costruito duce matrici in cui
sono registrate tutte le coppie di predecessori e successori,
T-LAB calcola le probabilità di
transizione (catene di markov) e fornisce vari output
concernenti le parole target.
Inoltre, è possibile eseguire una cluster analysis ed
esplorare le relazioni semantiche tra le parole sia all'interno
dell'intera rete che all'interno di 'cluster tematici' (N.B.: In
questo caso, l'algoritmo di clusterizzazione è costituito dal
'Louvain method' sviluppato da Blondel V.D., Guillame J.-L ,
Lambiotte R., Lefebre E., 2008. E, in T-LAB, la
tabella input è costituita da links 'directed' e
'weighted').
Ciò significa, dopo aver eseguito questo tipo di
analisi, l'utilizzatore può verificare le relazioni tra i nodi
della rete (cioè le parole chiave) a diversi livelli: a) in
relazioni del tipo uno-a-uno; b) all'interno di 'ego network'; c)
all'interno delle 'comunità' acui appartengono; d) all'interno
dell'intera rete costituita dal testo in analisi.
|
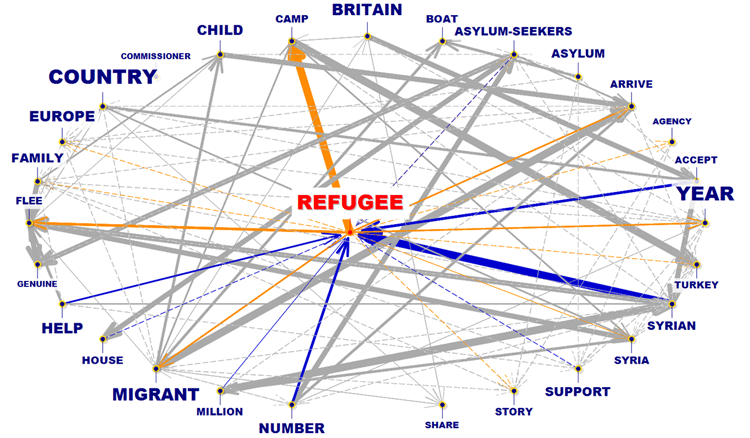
RELAZIONI DEL TIPO UNO-AD-UNO
|
EGO-NETWORK
|
|

|
|
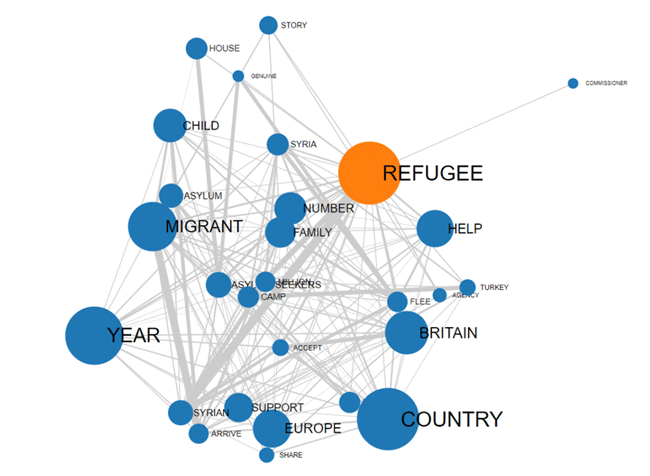
COMUNITA'
|
INTERA RETE
|

|
|
Le informazioni su come utilizzare le varie opzioni
di analisi sono organizzate in tre sezioni:
A - Esplorare le connessioni del tipo uno-a-uno e
le "ego network";
B - Esplorare le 'comunità' (cioè i cluster tematici) e l'intera
rete;
C - Alcuni dettagli tecnici.
N.B.: Per motivi editoriali, questa pagina include
esempi di analisi tratti da un corpus i cui testi sono in lingua
Inglese.
A - ESPLORARE LE CONNESSIONI DEL TIPO UNO-A-UNO
E LE "EGO NETWORK"
Quando l'analisi automatica è terminata, sono
disponibili diversi grafici e tabelle che consentono di verificare
le relazioni e i dati concernenti le parole chiave selezionate
(N.B.: A questo scopo è sufficiente un clic su un item delle
tabelle o su un qualsiasi punto mostrato nei grafici).
Tutti i grafici possono essere
personalizzati ed esportati in diversi formati (usare il pulsante
destro del mouse).
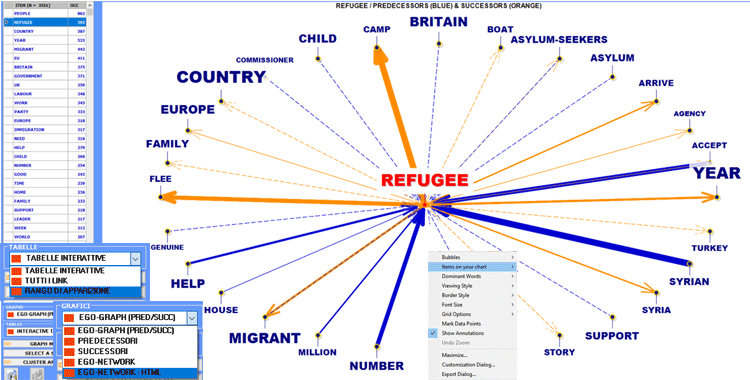
In due dei grafici gli elementi più vicini a quelli
selezionati sono quelli che hanno le probabilità più elevate di
venire prima (predecessori) o dopo (successori) di essi.
|
PREDECESSORI
|
SUCCESSORI
|
|
|
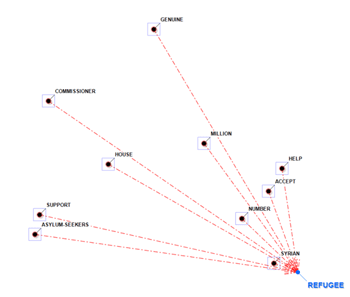
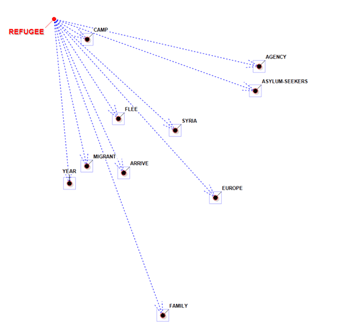
Negli altri casi, la vicinanza tra i termini-chiave
è rappresentata mediante i diversi spessori delle frecce che li
connettono (vedi immagini seguenti).
Tutti i dati possono essere verificati tramite vari
tipi di tabelle.
Nel dettaglio:
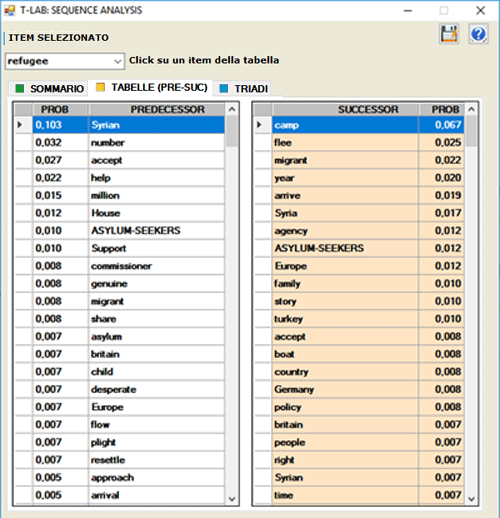
Le TABELLE INTERATTIVE mostrano le liste dei
predecessori e dei successori associati con le parole chiave
selezionate.
L'ordinamento è di tipo decrescente sui valori di
probabilità ("PROB"). Ad esempio, nella tabella seguente, la
probabilità che "camp" segua"refugee" è 0.067, ovvero pari al
6.7%.
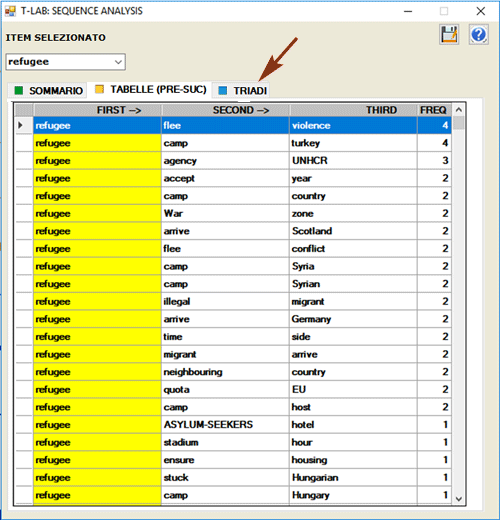
L'opzione TRIADI consente di visualizzare
alcune tabelle con sequenze di tre elementi in cui il lemma
selezionato è in prima, seconda o terza posizione. Per ciascuna
triade T-LAB riporta le
corrispondenti occorrenze. (N.B.: All'interno delle triadi, le
parole vuote non sono
incluse).
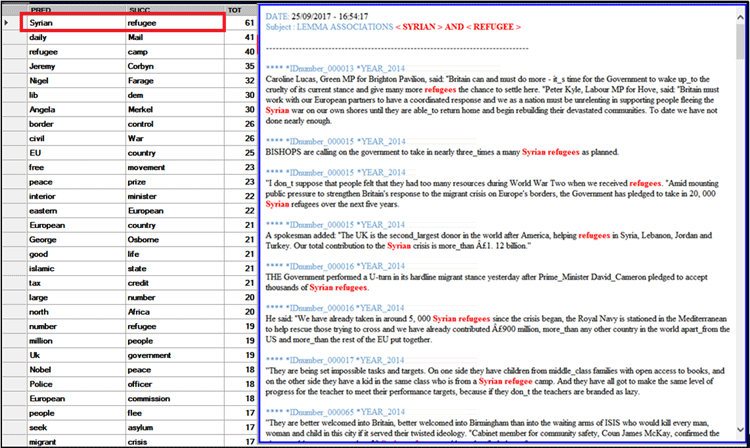
La tabella TUTTI I LINK (vedi sotto), che è
particolarmente utile per disambiguare i significati delle parole,
contiene tutte le coppie di predecessori e successori, e anche le
rispettive occorrenze.
Facendo clic su una riga di questa tabella, tutti i segmenti di
testo (cioè contesti elementari) in cui i due membri di ciascuna
coppia sono presenti allo stesso tempo (cioè co-occorrenze)
verranno visualizzati in formato HTML sul lato destro della
tabella.
La tabella RANGO DI APPARIZIONE, con la
frequenza e l'ordine medio di apparizione (o evocazione) di ogni
termine all'interno dei segmenti di testo, viene mostrata solo
quando il corpus è costituito da brevi testi, ad esempio risposte a
domande aperte.
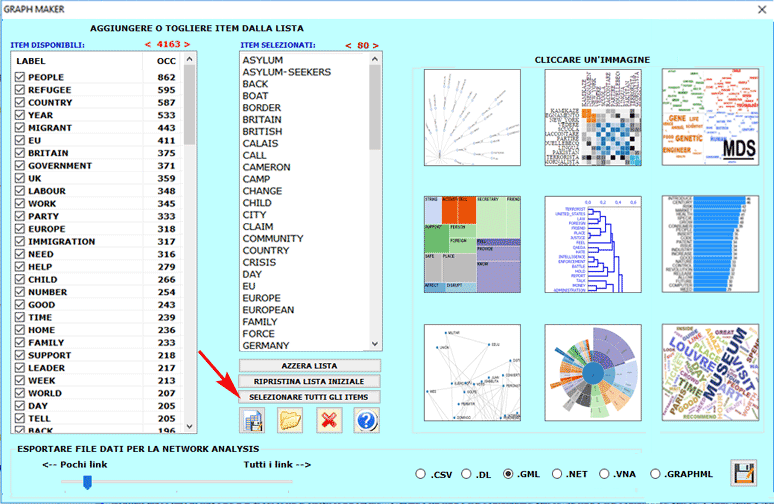
In qualsiasi momento, facendo clic sull'opzione
GRAPH MAKER, l'utente può creare diversi tipi di grafici
utilizzando elenchi personalizzati di parole chiave (vedi
sotto).
N.B.: Gli utenti esperti che sono interessati ad esportare file in
diversi formati (e.g., dl .gml .vna .graphml) con i dati relativi a
tutti i link, possono fare clic sul pulsante 'SELEZIONARE TUTTI GLI
ITEMS'.
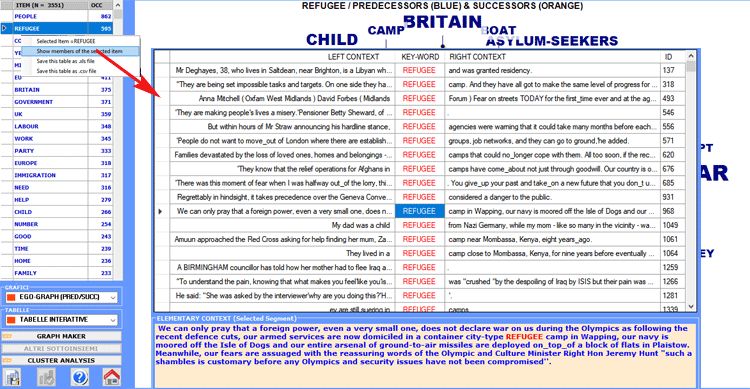
In qualsiasi momento, usando il tasto
destro sulle tabelle con le parole chiave, è possibile accedere
allo strumento Concordanze e verificare i contesti di
occorrenza dei vari item (vedi immagine seguente).
B -
ESPLORARE LE 'COMUNITÀ' (CIOÈ I CLUSTER TEMATICI) E L'INTERA
RETE
Quando si effettua un'analisi cluster, vengono resi
disponibili ulteriori grafici e tabelle che consentono di esplorare
tutti i livelli interni alla rete analizzata (vedi sotto gli item
contrassegnati con un piccolo rettangolo in colore blu).
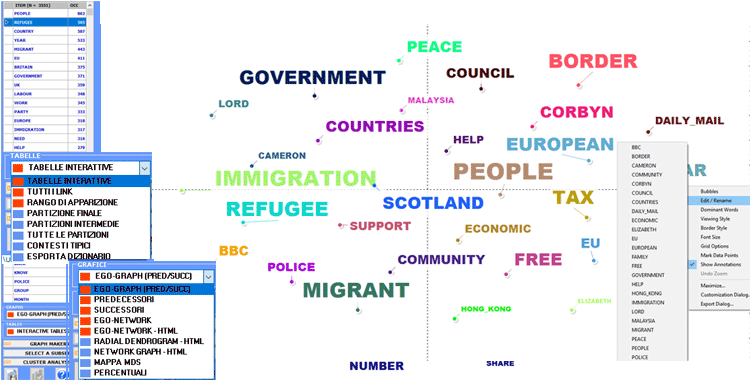
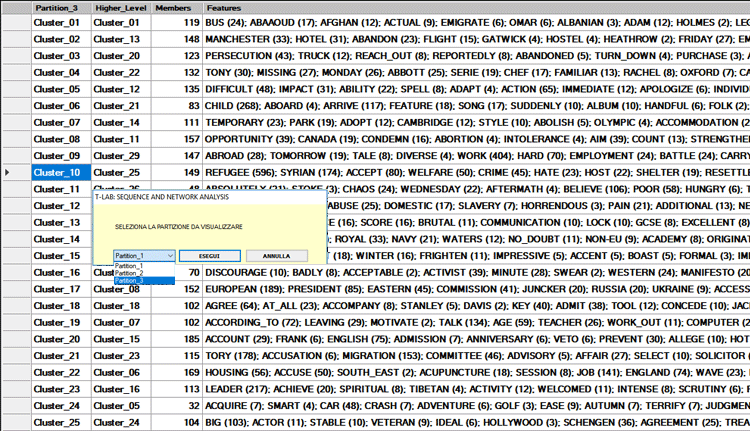
Una prima tabella riassume le caratteristiche (cioè
i termini chiave) della PARTIZIONE FINALE ottenuta
dall'algoritmo di clusterizzazione.
In tale tabella, le caratteristiche di ciascun cluster tematico
sono ordinate mediante il relativo valore TF-IDF (vedi
sotto).
N.B.: Quando un cluster della partizione finale
include solo due parole, di solito questo significa che un caso di
multiword non è stato risolto durante la fase di pre-trattamento
dei dati.
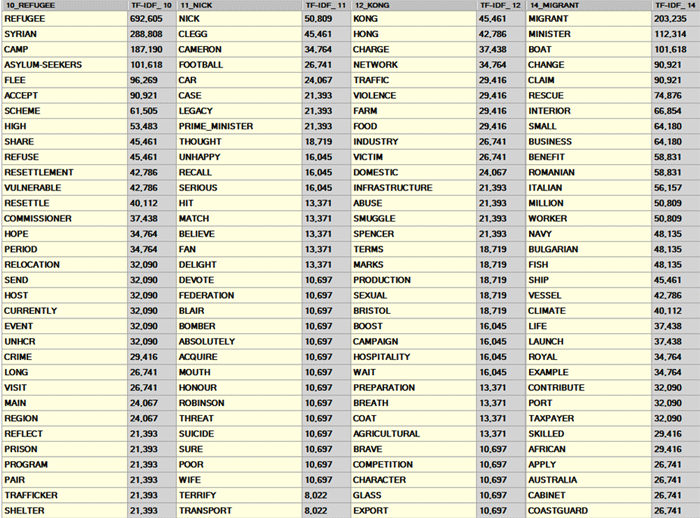
Facendo clic su una qualunque parola della tabella
PARTIZIONE FINALE (così come della tabella TUTTE LE
PARTIZIONI), un grafico dinamico del tipo TreeMap ci consente
di verificare le 'comunità' a cui essa risulta appartenere (vedi
sotto).
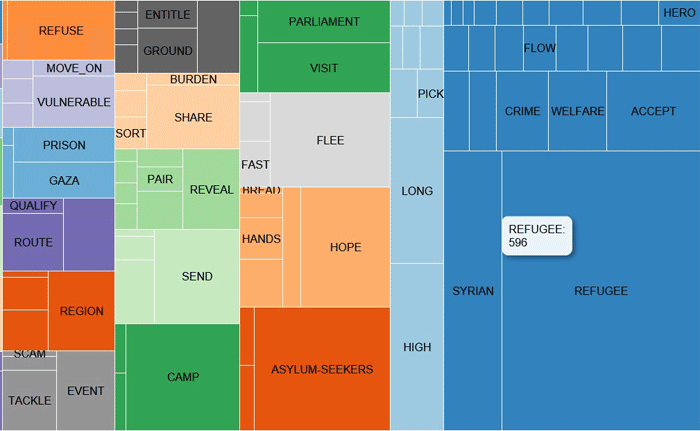
La MAPPA MDS e il grafico PERCENTUALI
(vedi sotto) ci permettono di verificare il 'peso' di ciascun
cluster, così come le relazioni tra i vari cluster all'interno
della migliore partizione (vedi sotto).
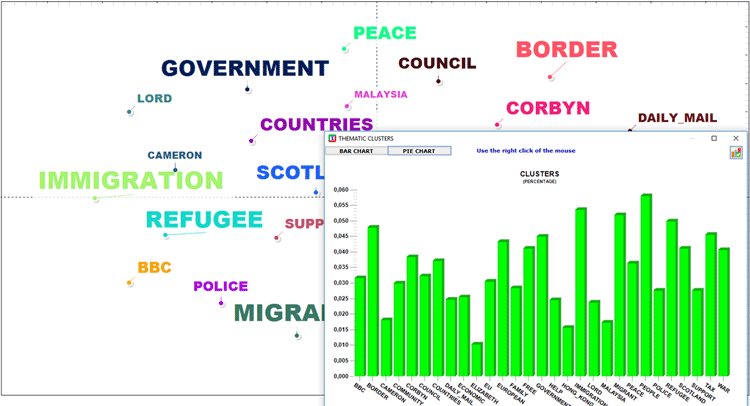
A seconda del numero di parole chiave, due grafici
in formato HTML ci permettono di verificare le loro relazioni sia
all'interno dell'intera rete che all'interno del cluster a cui
appartengono (vedi sotto).
|
DENDROGRAMMA RADIALE
|
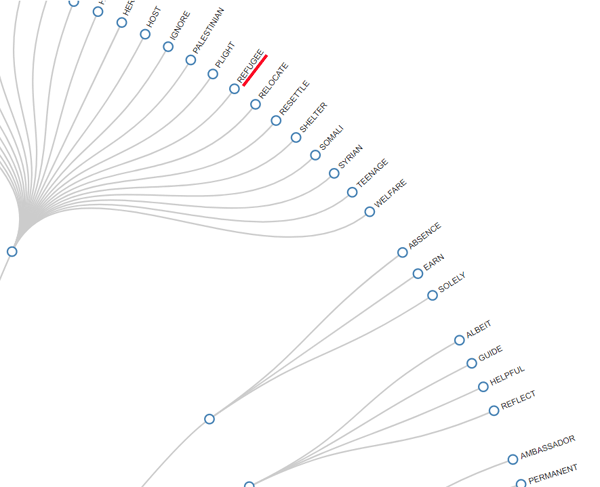
|
|
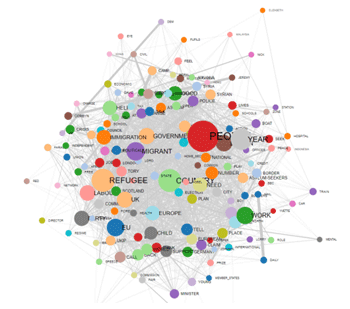
NETWORK (FORCE-DIRECTED GRAPH)
|
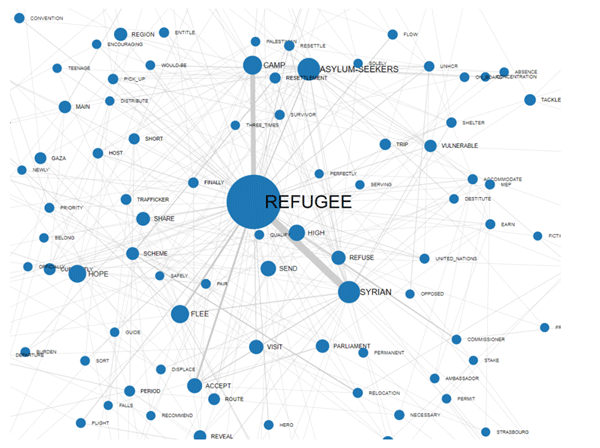
|
Due altre tabelle ci forniscono ulteriori
informazioni ottenute tramite la cluster analysis.
In particolare:
La tabella TUTTE LE PARTIZIONI consente di
verificare come le parole chiave sono state raggruppate in ciascuna
partizione della cluster analisi ((vedi immagine a seguire, dove i
numeri nelle colonne partitioni si riferiscono ai vari
cluster).
N.B.: Per impostazione predefinita, questa tabella viene presentata
ordinata sulla prima partizione (cioè quella con il maggior numero
di cluster), e ogni passaggio da un piccolo cluster all'altro è
marcato evidenziando in verde la prima parola che ad esso
appartiene.
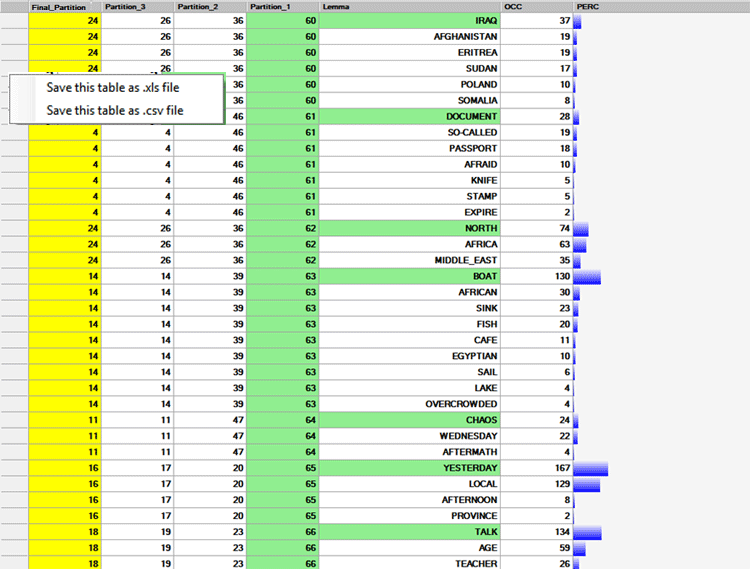
La tabella PARTIZIONI INTERMEDIE consente di
verificare come le parole-chiave sono state raggruppate all'interno
di ogni partizione selezionata. E, di volta in volta, le parole
caratteristiche di ogni cluster tematico sono ordinate per i valori
decrescenti delle loro occorrenze (vedi sotto).
La tabella CONTESTI TIPICI consente di
controllare i segmenti di testo che hanno il più alto punteggio di
associazione con i vari cluster della migliore partizione. In
questa tabella il "punteggio" si riferisce alla somiglianza (indice
coseno) tra il vettore delle caratteristiche di ciascun cluster e
il vettore in cui viene rappresentato ogni segmento di
testo.
N.B. Il segmento di testo più significativo di ciascun cluster è
evidenziato in giallo.

Come altri casi di analisi tematica, T-LAB permette
di esportare il dizionario della migliore partizione che può
essere utilizzato per ulteriori analisi.
C - ALCUNI DETTAGLI TECNICI
I tipi di sequenze che questo strumento T-LAB ci
consente di analizzare sono le seguenti:
1- Sequenze di Parole-Chiave, i cui elementi
sono unità lessicali (vale a dire parole o lemmi) presenti nel
corpus o in un sottoinsieme di esso. In questo caso il numero
massimo di 'nodi' (vale a dire i 'tipi' di unità lessicali) è
5.000;
N.B.: Quando viene applicata la lemmatizzazione
automatica, 5.000 unità lessicali corrispondono a circa 12,000
parole.
2- Sequenze di Temi, i cui elementi sono
unità di contesto (cioè contesti elementari) classificate da uno
strumento T-LAB per l'analisi tematica.
N.B.: In questo caso, poiché la sequenza dei
contesti elementari (frasi o paragrafi) caratterizza l'intera
'catena' (predecessori e successori) del corpus, T-LAB realizza
una forma specifica di analisi del discorso, i cui nodi
(vale a dire i 'temi') possono variare da un minimo 5 a un massimo
di 5.
3 - Sequenze archiviate in un file
Sequence.dat predisposto dall'utilizzatore (vedi relative
spiegazioni alla fine di questa sezione). In questo caso il numero
massimo di record è 50.000 e il numero di 'tipi' (ossia nodi) non
deve superare 5.000.
Le informazioni seguenti sono fornite per aiutare
l'utente a comprendere meglio i dati riportati nella tabella
SOMMARIO.
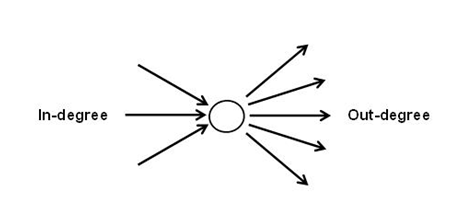
Secondo la teoria dei grafi, i predecessori e i
successori di ogni nodo (nel nostro caso, unità lessicali o temi)
possono essere rappresentati con delle frecce (archi) in ingresso
(in-degree = tipi di predecessori), o in uscita (out-degree = tipi
di successori).
Ad esempio, nella tabella seguente"people" ha 412
tipi di successori e 449 tipi of predecessori.
E il valore centrality degree è pari a 0.243.
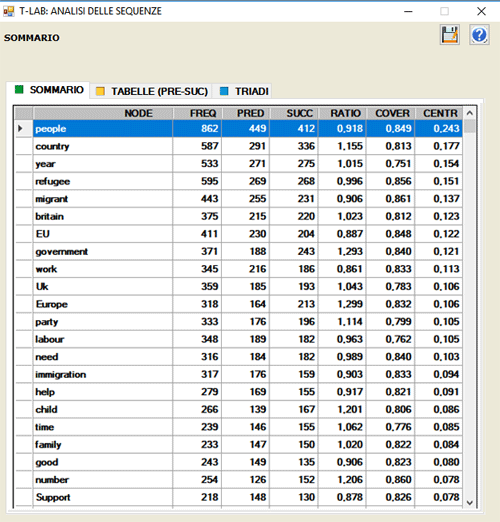
In base al loro rapporto (successori/predecessori),
è possibile verificare la varietà semantica generata dal nodo in
questione:
- se è maggiore di quanta ne riceve (ratio > 1),
il nodo è definito "sorgente";
- se è tanta quanta ne riceve (ratio = 1), il nodo è definito
"relais";
- se è minore di quanta ne riceve (ratio < 1), il nodo è
definito "assorbente".
Nella stessa tabella, per ogni unità lessicale, la
colonna "cover" (coverage) indica in che misura (percentuale) le
sue occorrenze sono precedute o seguite da unità lessicali incluse
nella lista definita dall'utilizzatore.
Quando le unità analizzate "coprono" la totalità di
quelle presenti nel corpus, il valore di "cover" è uguale a 1;
diversamente, è un valore inferiore.
Inoltre: quando il valore di "cover" è uguale a 1, anche la
sommatoria delle probabilità (sia per i predecessori che per i
successori) è uguale a 1; diversamente, è un valore inferiore.
In entrambi i casi, le percentuali "residue" sono determinate dal
fatto che vi sono predecessori e successori non inclusi
nell'analisi.
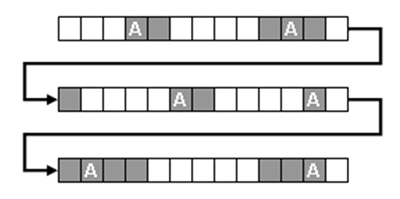
Si consideri ad esempio la sequenza rappresentata
nell'immagine seguente. Essa è costituita da 39 eventi: di questi,
solo 16 (le ipotetiche unità in analisi) sono "coperti" (quadratini
in grigio). Ciò a causa del fatto che alcuni di essi, ad esempio
quelli corrispondenti alle occorrenze dell'unità lessicale "A",
hanno come predecessori e successori anche unità lessicali non
incluse nell'analisi (quadratini in bianco).
Differentemente, quando l'utilizzatore analizza una
sequenza di temi o un file esterno tutti gli eventi sono
"coperti".
N.B.: Per analizzare un file esterno, l'utente deve
preparare il corrispondente file 'Sequence.dat'; quindi, dopo aver
aperto un progetto esistente, deve selezionare l' opzione "Sequenze
registrate in un file Sequence.dat".
Il metodo di calcolo e gli output (grafici e
tabelle) sono analoghi a quelli già descritti (vedi sopra).
Il file Sequence.dat, che può contenere ogni tipo
di sequenze (ad es. nomi degli interlocutori di una conversazione,
categorie ottenute mediante analisi di contenuto, nomi di eventi,
etc.), deve essere costituito da "N" record (min. 50 max 50.000),
ciascuno costituito da una label di max 50 caratteri, senza spazi
bianchi e senza segni di punteggiatura.
I tipi di eventi (tags) non devono essere più di
5.000.
La struttura del file Sequence.dat è quindi quella di un semplice
elenco (vedi esempi seguenti):
|
Hamlet
King
Hamlet
Queen
Hamlet
Queen
Hamlet
King
Queen
Hamlet
King
Hamlet
Horatio
Hamlet
Horatio
... ... ...
|
activist
food
genetic
conservative
activist
genetic
conservative
activist
commerce
conservative
activist
conservative
biology
society
activist
... ... ...
|
event_01
event_03
event_02
event_03
event_03
event_01
event_05
event_02
event_05
event_01
event_02
event_04
event_03
event_01
event_01
... ... ...
|
Sia nel caso delle sequenze concernenti le unità
lessicali (o temi) del corpus che nel caso delle sequenze
registrate in un file esterno (Sequence.dat), T-LAB produce alcune tabelle
collocate all'interno della cartella
MY-OUTPUT.
|